Fear Sells
Few SEOs took notice when Matt Cutts mentioned on TWIG that "breaking their spirits" was essential to stopping spammers. But that single piece of information add layers of insights around things like:
- duplicity on user privacy on organic versus AdWords
- benefit of the doubt for big brands versus absolute apathy toward smaller entities
- the importance of identity versus total wipeouts of those who are clipped
- mixed messaging on how to use disavow & the general fear around links
From Growth to No Growth
Some people internalize failure when growth slows or stops. One can't raise venture capital and keep selling the dream of the growth story unless the blame is internalized. If one understands that another dominant entity (monopoly) is intentionally subverting the market then a feel good belief in the story of unlimited growth flames out.
Most of the growth in the search channel is being absorbed by Google. In RKG's Q4 report they mentioned that mobile ad clicks were up over 100% for the year & mobile organic clicks were only up 28%.
Investing in Fear
There's a saying in investing that "genius is declining interest rates" but when the rates reverse the cost of that additional leverage surfaces. Risks from years ago that didn't really matter suddenly do.
The same is true with SEO. A buddy of mine mentioned getting a bad link example from Google where the link was in place longer than Google has been in existence. Risk can arbitrarily be added after the fact to any SEO activity. Over time Google can keep shifting the norms of what is acceptable. So long as they are fighting off Wordpress hackers and other major issues they are kept busy, but when they catch up on that stuff they can then focus on efforts to shift white to gray and gray to black - forcing people to abandon techniques which offered a predictable positive ROI.
Defunding SEO is an essential & virtuous goal.
Hiding data (and then giving crumbs of it back to profile webmasters) is one way of doing it, but adding layers of risk is another. What panda did to content was add a latent risk to content where the cost of that risk in many cases vastly exceeded the cost of the content itself. What penguin did to links was the same thing: make the latent risk much larger than the upfront cost.
As Google dials up their weighting on domain authority many smaller sites which competed on legacy relevancy metrics like anchor text slide down the result set. When they fall down the result set, many of those site owners think they were penalized (even if their slide was primarily driven by a reweighting of factors rather than an actual penalty). Since there is such rampant fearmongering on links, they start there. Nearly every widely used form of link building has been promoted by Google engineers as being spam. 
- Paid links? Spam.
- Reciprocal links? Spam.
- Blog comments? Spam.
- Forum profile links? Spam.
- Integrated newspaper ads? Spam.
- Article databases? Spam.
- Designed by credit links? Spam.
- Press releases? Spam.
- Web 2.0 profile & social links? Spam.
- Web directories? Spam.
- Widgets? Spam.
- Infographics? Spam.
- Guest posts? Spam.
It doesn't make things any easier when Google sends out examples of spam links which are sites the webmaster has already disavowed or sites which Google explicitly recommended in their webmaster guidelines, like DMOZ.
It is quite the contradiction where Google suggests we should be aggressive marketers everywhere EXCEPT for SEO & basically any form of link building is far too risky.
It’s a strange world where when it comes to social media, Google is all promote promote promote. Or even in paid search, buy ads, buy ads, buy ads. But when it comes to organic listings, it’s just sit back and hope it works, and really don’t actively go out and build links, even those are so important. - Danny Sullivan
Google is in no way a passive observer of the web. Rather they actively seek to distribute fear and propaganda in order to take advantage of the experiment effect.
They can find and discredit the obvious, but most on their “spam list” done “well” are ones they can’t detect. So, it’s easier to have webmasters provide you a list (disavows), scare the ones that aren’t crap sites providing the links into submission and damn those building the links as “examples” – dragging them into town square for a public hanging to serve as a warning to anyone who dare disobey the dictatorship. - Sugarrae
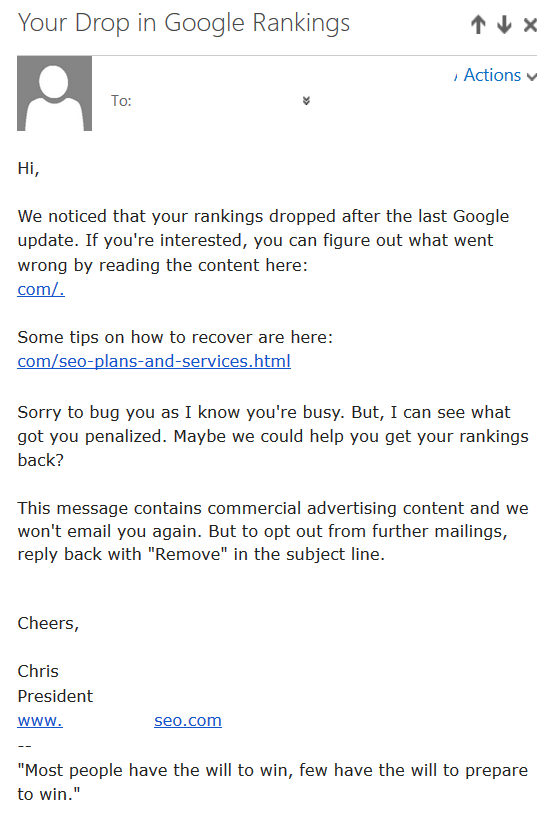
This propaganda is so effective that email spammers promoting "SEO solutions" are now shifting their pitches from grow your business with SEO to recover your lost traffic
Where Do Profits Come From?
I saw Rand tweet this out a few days ago...
... and thought "wow, that couldn't possibly be any less correct."
When ecosystems are stable you can create processes which are profitable & pay for themselves over the longer term.
I very frequently get the question: 'what’s going to change in the next 10 years?' And that is a very interesting question; it’s a very common one. I almost never get the question: 'what’s not going to change in the next 10 years?' And I submit to you that that second question is actually the more important of the two – because you can build a business strategy around the things that are stable in time….in our retail business, we know that customers want low prices and I know that’s going to be true 10 years from now. They want fast delivery, they want vast selection. It’s impossible to imagine a future 10 years from now where a customer comes up and says, 'Jeff I love Amazon, I just wish the prices were a little higher [or] I love Amazon, I just wish you’d deliver a little more slowly.' Impossible. And so the effort we put into those things, spinning those things up, we know the energy we put into it today will still be paying off dividends for our customers 10 years from now. When you have something that you know is true, even over the long-term, you can afford to put a lot of energy into it. - Jeff Bezos at re: Invent, November, 2012
When ecosystems are unstable, anything approaching boilerplate has an outsized risk added by the dominant market participant. The quicker your strategy can be done at scale or in the third world, the quicker Google shifts it from a positive to a negative ranking signal. It becomes much harder to train entry level employees on the basics when some of the starter work they did in years past now causes penalties. It becomes much harder to manage client relationships when their traffic spikes up and down, especially if Google sends out rounds of warnings they later semi-retract.
What's more, anything that is vastly beyond boilerplate tends to require a deeper integration and a higher level of investment - making it take longer to pay back. But the budgets for such engagement dry up when the ecosystem itself is less stable. Imagine the sales pitch, "I realize we are off 35% this year, but if we increase the budget 500% we should be in a good spot a half-decade from now."
All great consultants aim to do more than the bare minimum in order to give their clients a sustainable competitive advantage, but by removing things which are scalable and low risk Google basically prices out the bottom 90% to 95% of the market. Small businesses which hire an SEO are almost guaranteed to get screwed because Google has made delivering said services unprofitable, particularly on a risk-adjusted basis.
Being an entrepreneur is hard. Today Google & Amazon are giants, but it wasn't always that way. Add enough risk and those streams of investment in innovation disappear. Tomorrow's Amazon or Google of other markets may die a premature death. You can't see what isn't there until you look back from the future - just like the answering machine AT&T held back from public view for decades.
Meanwhile, the Google Venture backed companies keep on keeping on - they are protected.
When ad agencies complain about the talent gap, what they are really complaining about is paying people what they are worth. But as the barrier to entry in search increases, independent players die, leaving more SEOs to chase fewer corporate jobs at lower wages. Even companies servicing fortune 500s are struggling.
On an individual basis, creating value and being fairly compensated for the value you create are not the same thing. Look no further than companies like Google & Apple which engage in flagrantly illegal anti-employee cartel agreements. These companies "partnered" with their direct competitors to screw their own employees. Even if you are on a winning team it does not mean that you will be a winner after you back out higher living costs and such illegal employer agreements.
This is called now the winner-take-all society. In other words the rewards go overwhelmingly to just the thinnest crust of folks. The winner-take-all society creates incredibly perverse incentives to become a cheater-take-all society. Cause my chances of winning an honest competition are very poor. Why would I be the one guy or gal who would be the absolute best in the world? Why not cheat instead?" - William K Black
Meanwhile, complaints about the above sorts of inequality or other forms of asset stripping are pitched as being aligned with Nazi Germany's treatment of Jews. Obviously we need more H-1B visas to further drive down wages even as graduates are underemployed with a mountain of debt.
A Disavow For Any (& Every) Problem
Removing links is perhaps the single biggest growth area in SEO.
Just this week I got an unsolicited email from an SEO listing directory
We feel you may qualify for a Top position among our soon to be launched Link Cleaning Services Category and we would like to learn more about Search Marketing Info. Due to the demand for link cleaning services we're poised to launch the link cleaning category. I took a few minutes to review your profile and felt you may qualify. Do you have time to talk this Monday or Tuesday?
Most of the people I interact with tend to skew toward the more experienced end of the market. Some of the folks who join our site do so after their traffic falls off. In some cases the issues look intimately tied to Panda & the sites with hundreds of thousands of pages maybe only have a couple dozen inbound links. In spite of having few inbound links & us telling people the problem looks to be clearly aligned with Panda, some people presume that the issue is links & they still need to do a disavow file.
Why do they make that presumption? It's the fear message Google has been selling nonstop for years.
Punishing people is much different, and dramatic, from not rewarding. And it feeds into the increasing fear that people might get punished for anything. - Danny Sullivan
 What happens when Google hands out free all-you-can-eat gummy bear laxatives to children at the public swimming pool? A tragedy of the commons.
What happens when Google hands out free all-you-can-eat gummy bear laxatives to children at the public swimming pool? A tragedy of the commons.
Rather than questioning or countering the fear stuff, the role of the SEO industry has largely been to act as lap dogs, syndicating & amplifying the fear.
- link tool vendors want to sell proprietary clean up data
- SEO consultants want to tell you that they are the best and if you work with someone else there is a high risk hidden in the low price
- marketers who crap on SEO to promote other relabeled terms want to sell you on the new term and paint the picture that SEO is a self-limiting label & a backward looking view of marketing
- paid search consultants want to enhance the perception that SEO is unreliable and not worthy of your attention or investment
Even entities with a 9 figure valuation (and thus plenty of resources to invest in a competent consultant) may be incorrectly attributing SEO performance problems to links.
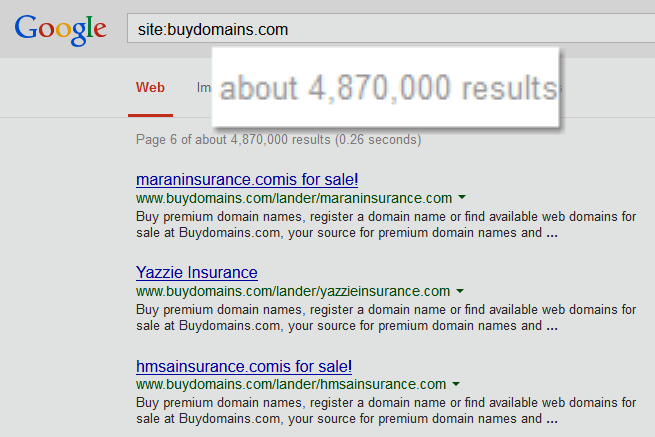
A friend recently sent me a link removal request from Buy Domains referring to a post which linked to them.

On the face of this, it's pretty absurd, no? A company which does nothing but trade in names themselves asks that their name reference be removed from a fairly credible webpage recommending them.
The big problem for Buy Domains is not backlinks. They may have had an issue with some of the backlinks from PPC park pages in the past, but now those run through a redirect and are nofollowed.
Their big issue is that they have less than great engagement metrics (as do most marketplace sites other than eBay & Amazon which are not tied to physical stores). That typically won't work if the entity has limited brand awareness coupled with having nearly 5 million pages in Google's index.
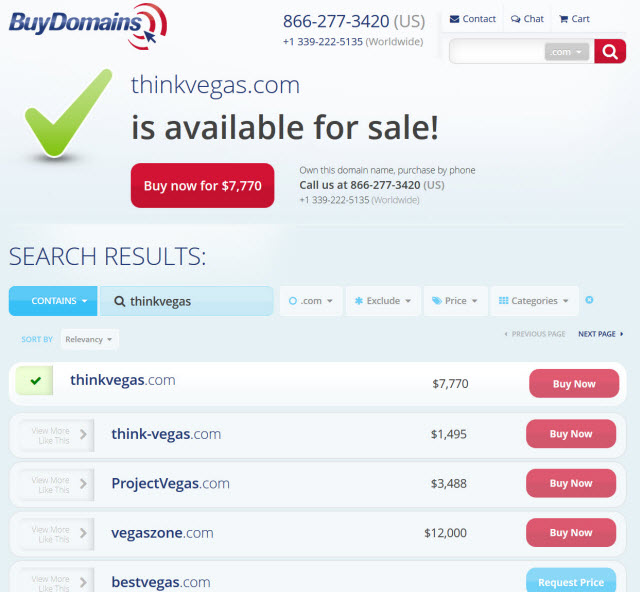
They not only have pages for each individual domain name, but they link to their internal search results from their blog posts & those search pages are indexed. Here's part of a recent blog post

And here are examples of the thin listing sorts of pages which Panda was designed in part to whack. These pages were among the millions indexed in Google.

A marketplace with millions of pages that doesn't have broad consumer awareness is likely to get nailed by Panda. And the websites linking to it are likely to end up in disavow files, not because they did anything wrong but because Google is excellent at nurturing fear.
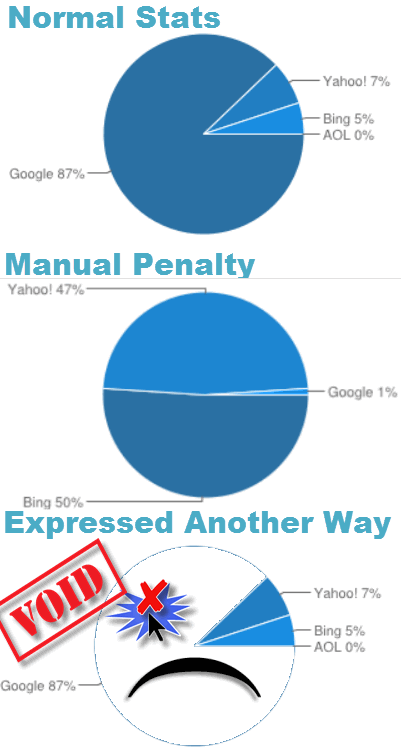
What a Manual Penalty Looks Like
Expedia saw a 25% decline in search visibility due to an unnatural links penalty , causing their stock to fall 6.4%. Both Google & Expedia declined to comment. It appears that the eventual Expedia undoing stemmed from Hacker News feedback & coverage about an outing story on an SEO blog that certainly sounded like it stemmed from an extortion attempt. USA Today asked if the Expedia campaign was a negative SEO attack.
While Expedia's stock drop was anything but trivial, they will likely recover within a week to a month.
Smaller players can wait and wait and wait and wait ... and wait.
Manual penalties are no joke, especially if you are a small entity with no political influence. The impact of them can be absolutely devastating. Such penalties are widespread too.
In Google's busting bad advertising practices post they highlighted having zero tolerance, banning more than 270,000 advertisers, removing more than 250,000 publishers accounts, and disapproving more than 3,000,000 applications to join their ad network. All that was in 2013 & Susan Wojcicki mentioned Google having 2,000,000 sites in their display ad network. That would mean that something like 12% of their business partners were churned last year alone.
If Google's churn is that aggressive on their own partners (where Google has an economic incentive for the relationship) imagine how much broader the churn is among the broader web. In this video Matt Cutts mentioned that Google takes over 400,000 manual actions each month & they get about 5,000 reconsideration request messages each week, so over 95% of the sites which receive notification never reply. Many of those who do reply are wasting their time.
The Disavow Threat
Originally when disavow was launched it was pitched as something to be used with extreme caution:
This is an advanced feature and should only be used with caution. If used incorrectly, this feature can potentially harm your site’s performance in Google’s search results. We recommend that you disavow backlinks only if you believe you have a considerable number of spammy, artificial, or low-quality links pointing to your site, and if you are confident that the links are causing issues for you. In most cases, Google can assess which links to trust without additional guidance, so most normal or typical sites will not need to use this tool.
Recently Matt Cutts has encouraged broader usage. He has one video which discusses proatively disavowing bad links as they come in & another where he mentioned how a large company disavowed 100% of their backlinks that came in for a year.
The idea of proactively monitoring your backlink profile is quickly becoming mainstream - yet another recurring fixed cost center in SEO with no upside to the client (unless you can convince the client SEO is unstable and they should be afraid - which would ultimately retard their longterm investment in SEO).
Given the harshness of manual actions & algorithms like Penguin, they drive companies to desperation, acting irrationally based on fear.
People are investing to undo past investments. It's sort of like riding a stock down 60%, locking in the losses by selling it, and then using the remaining 40% of the money to buy put options or short sell the very same stock. :D
Some companies are so desperate to get links removed that they "subscribe" sites that linked to them organically with spam email messages asking the links be removed.
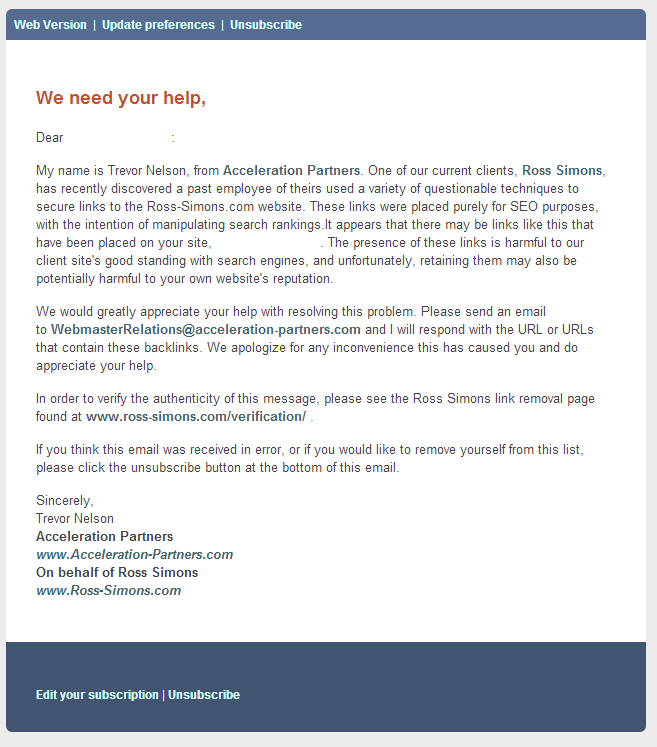
Some go so far that they not only email you on and on, but they created dedicated pages on their site claiming that the email was real.
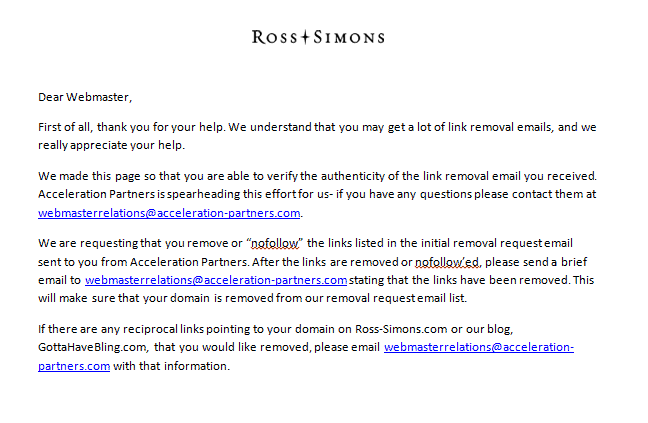
What's so risky about the above is that many webmasters will remove links sight unseen, even from an anonymous Gmail account. Mix in the above sort of "this message is real" stuff and how easy would it be for a competitor to target all your quality backlinks with a "please remove my links" message? Further, how easy would it be for a competitor aware of such a campaign to drop a few hundred Dollars on Fiverr or Xrummer or other similar link sources, building up your spam links while removing your quality links?
A lot of the "remove my link" messages are based around lying to the people who are linking & telling them that the outbound link is harming them as well: "As these links are harmful to both yours and our business after penguin2.0 update, we would greatly appreciate it if you would delete these backlinks from your website."
Here's the problem though. Even if you spend your resources and remove the links, people will still likely add your site to their disavow file. I saw a YouTube video recording of an SEO conference where 4 well known SEO consultants mentioned that even if they remove the links "go ahead and disavow anyhow," so there is absolutely no upside for publishers in removing links.
How Aggregate Disavow Data Could Be Used
Recovery is by no means guaranteed. In fact of the people who go to the trouble to remove many links & create a disavow file, only 15% of people claim to have seen any benefit.
The other 85% who weren't sure of any benefit may not have only wasted their time, but they may have moved some of their other projects closer toward being penalized.

Let's look at the process:
- For the disavow to work you also have to have some links removed.
- Some of the links that are removed may not have been the ones that hurt you in Google, thus removing them could further lower your rank.
- Some of the links you have removed may be the ones that hurt you in Google, while also being ones that helped you in Bing.
- The Bing & Yahoo! Search traffic hit comes immediately, whereas the Google recovery only comes later (if at all).
- Many forms of profits (from client services or running a network of sites) come systematization. If you view everything that is systematized or scalable as spam, then you are not only disavowing to try to recover your penalized site, but you are send co-citation disavow data to Google which could have them torch other sites connected to those same sources.
- If you run a network of sites & use the same sources across your network and/or cross link around your network, you may be torching your own network.
- If you primarily do client services & disavow the same links you previously built for past clients, what happens to the reputation of your firm when dozens or hundreds of past clients get penalized? What happens if a discussion forum thread on Google Groups or elsewhere starts up where your company gets named & then a tsunami of pile on stuff fills out in the thread? Might that be brand destroying?
The disavow and review process is not about recovery, but is about collecting data and distributing pain in a game of one-way transparency. Matt has warned that people shouldn't lie to Google...
...however Google routinely offers useless non-information in their responses.
Some Google webmaster messages leave a bit to be desired.
Recovery is uncommon. Your first response from Google might take a month or more. If you work for a week or two on clean up and then the response takes a month, the penalty has already lasted at least 6 weeks. And that first response might be something like this
Reconsideration request for site.com: Site violates Google's quality guidelines
We received a reconsideration request from a site owner for site.com/.
We've reviewed your site and we believe that site.com/ still violates our quality guidelines. In order to preserve the quality of our search engine, pages from site.com/ may not appear or may not rank as highly in Google's search results, or may otherwise be considered to be less trustworthy than sites which follow the quality guidelines.
For more specific information about the status of your site, visit the Manual Actions page in Webmaster Tools. From there, you may request reconsideration of your site again when you believe your site no longer violates the quality guidelines.
If you have additional questions about how to resolve this issue, please see our Webmaster Help Forum.
Absolutely useless.
Zero useful information whatsoever.
As people are unsuccessful in the recovery process they cut deeper and deeper. Some people have removed over 90% of their profile without recovering & been nearly a half-year into the (12-step) "recovery" process before even getting a single example of a bad link from Google. In some cases these bad links Google identified were links were obviously created by third party scraper sites & were not in Google's original sample of links to look at (so even if you looked at every single link they showed you & cleaned up 100% of issues you would still be screwed.)
Another issue with aggregate disavow data is there is a lot of ignorance in the SEO industry in general, and people who try to do things cheap (essentially free) at scale have an outsized footprint in the aggregate data. For instance, our site's profile links are nofollowed & our profiles are not indexed by Google. In spite of this, examples like the one below are associated with not 1 but 3 separate profiles for a single site.
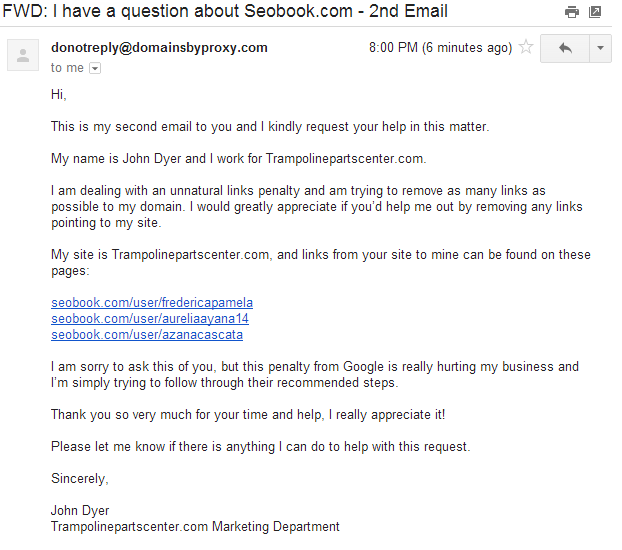
Our site only has about 20,000 to 25,000 unique linking domains. However over the years we have had well over a million registered user profiles. If only 2% of the registered user profiles were ignorant spammers who spammed our profile pages and then later added our site to a disavow file, we would have more people voting *against* our site than we have voting for it. And that wouldn't be because we did anything wrong, but rather because Google is fostering an environment of mixed messaging, fear & widespread ignorance.
And if we are ever penalized, the hundreds of scraper sites built off scraping our RSS feed would make the recovery process absolutely brutal.
Another factor with Google saying "you haven't cut out enough bone marrow yet" along with suggesting that virtually any/every type of link is spam is that there is going to be a lot of other forms of false positives in the aggregate data.
I know some companies specializing in link recovery which in part base some aspects of their disavows on the site's ranking footprint. Well if you get a manual penalty, a Panda penalty, or your site gets hacked, then those sorts of sites which you are linking to may re-confirm that your site deserves to be penalized (on a nearly automated basis with little to no thought) based on the fact that it is already penalized. Good luck on recovering from that as Google folds in aggregate disavow data to justify further penalties.

Responsibility
All large ecosystems are gamed. We see it with app ratings & reviews, stealth video marketing, advertising, malware installs, and of course paid links.
Historically in search there has been the view that you are responsible for what you have done, but not the actions of others. The alternate roadmap would lead to this sort of insanity:
Our system has noticed that in the last week you received 240 spam emails. In result, your email account was temporarily suspended. Please contact the spammers and once you have a proof they unsuscribed you from their spam databases, we will reconsider reopening your email account.
As Google has closed down their own ecosystem, they allow their own $0 editorial to rank front & center even if it is pure spam, but third parties are now held to a higher standard - you could be held liable for the actions of others.
At the extreme, one of Google's self-promotional automated email spam messages sent a guy to jail. In spite of such issues, Google remains unfazed, adding a setting which allows anyone on Google+ to email other members.
Ask Google if they should be held liable for the actions of third parties and they will tell you to go to hell. Their approach to copyright remains fuzzy, they keep hosting more third party content on their own sites, and even when that content has been deemed illegal they scream that it undermines their first amendment rights if they are made to proactively filter:
Finally, they claimed they were defending free speech. But it's the courts which said the pictures were illegal and should not be shown, so the issue is the rule of law, not freedom of speech.
...
the non-technical management, particularly in the legal department, seems to be irrational to the point of becoming adolescent. It's almost as if they refuse to do something entirely sensible, and which would save them and others time and trouble, for no better reason than that someone asked them to.
Monopolies with nearly unlimited resources shall be held liable for nothing.
Individuals with limited resources shall be liable for the behavior of third parties.
Google Duplicity (beta).
Torching a Competitor
As people have become more acclimated toward link penalties, a variety of tools have been created to help make sorting through the bad ones easier.
"There have been a few tools coming out on the market since the first Penguin - but I have to say that LinkRisk wins right now for me on ease of use and intuitive accuracy. They can cut the time it takes to analyse and root out your bad links from days to minutes..." - Dixon Jones
But as there have been more tools created for sorting out bad links & more tools created to automate sending link emails, two things have happened
- Google is demanding more links be removed to allow for recovery
- people are becoming less responsive to link removal requests as they get bombarded with them
- Some of these tools keep bombarding people over and over again weekly until the link is removed or the emails go to the spam bin
- to many people the link removal emails are the new link request emails ;)
- one highly trusted publisher who participates in our forums stated they filtered the word "disavow" to automatically go to their trash bin
- on WebmasterWorld a member decided it was easier to delete their site than deal with the deluge of link removal spam emails
The problem with Google rewarding negative signals is there are false positives and it is far cheaper to kill a business than it is to build one. The technically savvy teenager who created the original version of the software used in the Target PoS attack sold the code for only $2,000.
There have been some idiotic articles like this one on The Awl suggesting that comment spamming is now dead as spammers run for the hills, but that couldn't be further from the truth. Some (not particularly popular) blogs are getting hundreds to thousands of spam comments daily & Wordpress can have trouble even backing up the database (unless the comment spam is regularly deleted) as the database can quickly get a million records.
The spam continues but the targets change. A lot of these comments are now pointed at YouTube videos rather than ordinary websites.
As Google keeps leaning into negative signals, one can expect a greater share of spam links to be created for negative SEO purposes.
Maybe this maternity jeans comment spam is tied to the site owner, but if they didn't do it, how do they prove it?
Once again, I'll reiterate Bill Black
This is called now the winner-take-all society. In other words the rewards go overwhelmingly to just the thinnest crust of folks. The winner-take-all society creates incredibly perverse incentives to become a cheater-take-all society. Cause my chances of winning an honest competition are very poor. Why would I be the one guy or gal who would be the absolute best in the world? Why not cheat instead?" - William K Black
The cost of "an academic test" can be as low as $5. You know you might be in trouble when you see fiverr.com/conversations/theirusername in your referrers:
Our site was hit with negative SEO. We have manually collected about 24,000 bad links for our disavow file (so far). It probably cost the perp $5 on Fiverr to point these links at our site. Do you want to know how bad that sucks? I'll tell you. A LOT!! Google should be sued enmass by web masters for wasting our time with this "bad link" nonsense. For a company with so many Ph.D's on staff, I can't believe how utterly stupid they are
Or, worse yet, you might see SAPE in your referrers
And if the attempt to get you torched fails, they can try & try again. The cost of failure is essentially zero. They can keep pouring on the fuel until the fire erupts.
 Even Matt Cutts complains about website hacking, but that doesn't mean you are free of risk if someone else links to your site from hacked blogs. I've been forwarded unnatural link messages from Google which came about after person's site was added in on a SAPE hack by a third party in an attempt to conceal who the beneficial target was. When in doubt, Google may choose to blame all parties in a scorched Earth strategy.
Even Matt Cutts complains about website hacking, but that doesn't mean you are free of risk if someone else links to your site from hacked blogs. I've been forwarded unnatural link messages from Google which came about after person's site was added in on a SAPE hack by a third party in an attempt to conceal who the beneficial target was. When in doubt, Google may choose to blame all parties in a scorched Earth strategy.
If you get one of those manual penalties, you're screwed.
Even if you are not responsible for such links, and even if you respond on the same day, and even if Google believes you, you are still likely penalized AT LEAST for a month. Most likely Google will presume you are a liar and you have at least a second month in the penalty box. To recover you might have to waste days (weeks?) of your life & remove some of your organic links to show that you have went through sufficient pain to appease the abusive market monopoly.
As bad as the above is, it is just the tip of the iceberg.
- People can redirect torched websites.
- People can link to you from spam link networks which rotate links across sites, so you can't possibly remove or even disavow all the link sources.
- People can order you a subscription of those rotating spam links from hacked sites, where new spam links appear daily. Google mentioned discovering 9,500 malicious sites daily & surely the number has only increased from there.
- People can tie any/all of the above with cloaking links or rel=canonical messages to GoogleBot & then potentially chain that through further redirects cloaked to GoogleBot.
- And on and on ... the possibilities are endless.
Extortion
 Another thing this link removal fiasco subsidizes is various layers of extortion.
Another thing this link removal fiasco subsidizes is various layers of extortion.
Not only are there the harassing emails threatening to add sites to disavow lists if they don't remove the links, but some companies quickly escalate things from there. I've seen hosting abuse, lawyer threat letters, and one friend was actually sued in court (and the people who sued him actually had the link placed!)
Google created a URL removal tool which allows webmasters to remove pages from third party websites. How long until that is coupled with DDoS attacks? Once effective with removing one page, a competitor might decide to remove another.
Another approach to get links removed is to offer payment. But payment itself might encourage the creation of further spammy links as link networks look to replace their old cashflow with new sources.
The recent Expedia fiasco started as an extortion attempt: "If I wanted him to not publish it, he would "sell the post to the highest bidder."
Another nasty issue here is articles like this one on Link Research Tools, where they not only highlight client lists of particular firms, but then state which URLs have not yet been penalized followed by "most likely not yet visible." So long as that sort of "publishing" is acceptable in the SEO industry, you can bet that some people will hire the SEOs nearly guaranteeing a penalty to work on their competitor's sites, while having an employee write a "case study" for Link Research Tools. Is this the sort of bullshit we really want to promote?
Some folks are now engaging in overt extortion:
I had a client phone me today and say he had a call from a guy with an Indian accent who told him that he will destroy his website rankings if he doesn't pay him £10 per month to NOT do this.
Branding / Rebranding / Starting Over
Sites that are overly literal in branding likely have no chance at redemption. That triple hyphenated domain name in a market that is seen as spammy has zero chance of recovery.
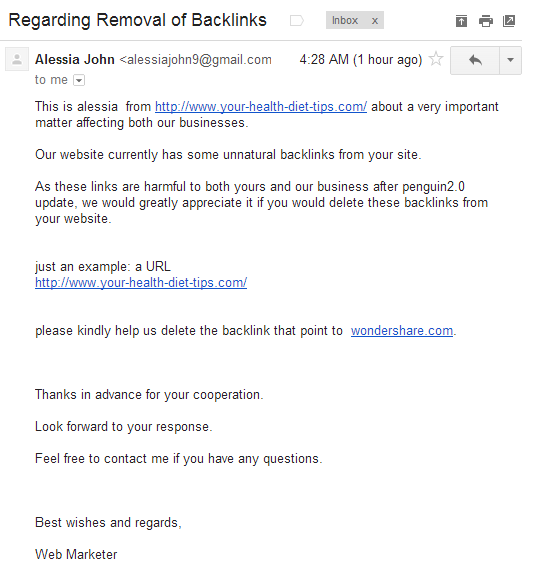
Even being a generic unbranded site in a YMYL category can make you be seen as spam. The remote rater documents stated that the following site was spam...
... even though the spammiest thing on it was the stuff advertised in the AdSense ads:
For many (most?) people who receive a manual link penalty or are hit by Penguin it is going to be cheaper to start over than to clean up.
At the very minimum it can make sense to lay groundwork for a new project immediately just in case the old site can't recover or takes nearly a year to recover. However, even if you figure out the technical bits, as soon as you have any level of success (or as soon as you connect your projects together in any way) you once again become a target.
And you can't really invest in higher level branding functions unless you think the site is going to be around for many years to earn off the sunk cost.

Succeeding at SEO is not only about building rank while managing cashflow and staying unpenalized, but it is also about participating in markets where you are not marginalized due to Google inserting their own vertical search properties.
Even companies which are large and well funded may not succeed with a rebrand if Google comes after their vertical from the top down.
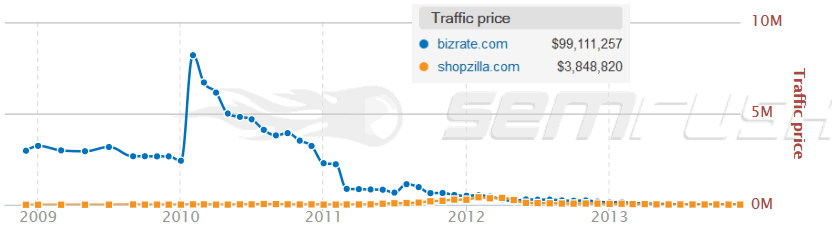
Hope & Despair
If you are a large partner affiliated with Google, hope is on your side & you can monetize the link graph: "By ensuring that our clients are pointing their links to maximize their revenue, we’re not only helping them earn more money, but we’re also stimulating the link economy."
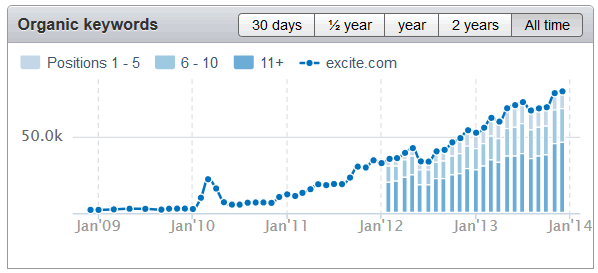
You have every reason to be Excited, as old projects like Excite or Merchant Circle can be relaunched again and again.
Even smaller players with the right employer or investor connections are exempt from these arbitrary risks.
You can even be an SEO and start a vertical directory knowing you will do well if you can get that Google Ventures investment, even as other similar vertical directories were torched by Panda.
For most other players in that same ecosystem, the above tailwind is a headwind. Don't expect much 1 on 1 help in webmaster tools.
In this video Matt Cutts mentioned that Google takes over 400,000 manual actions each month & they get about 5,000 reconsideration request messages each week, so over 95% of the sites which receive notification never reply. Many of those who reply are wasting their time. How many confirmed Penguin 1.0 recoveries are you aware of?
Even if a recovery is deserved, it does not mean one will happen, as errors do happen. And on the off chance recovery happens, recovery does not mean a full restoration of rankings.
There are many things we can learn from Google's messages, but probably the most important is this:
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to heaven, we were all going direct the other way - in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only. - Charles Dickens, A Tale of Two Cities










{kind=link}
{kind=link}