Anyone can argue about the intent of a particular action & the outcome that is derived by it. But when the outcome is known, at some point the intent is inferred if the outcome is derived from a source of power & the outcome doesn't change.
Or, put another way, if a powerful entity (government, corporation, other organization) disliked an outcome which appeared to benefit them in the short term at great lasting cost to others, they could spend resources to adjust the system.
If they don't spend those resources (or, rather, spend them on lobbying rather than improving the ecosystem) then there is no desired change. The outcome is as desired. Change is unwanted.
News is a stock vs flow market where the flow of recent events drives most of the traffic to articles. News that is more than a couple days old is no longer news. A news site which stops publishing news stops becoming a habit & quickly loses relevancy. Algorithmically an abandoned archive of old news articles doesn't look much different than eHow, in spite of having a much higher cost structure.
According to SEMrush's traffic rank, ampproject.org gets more monthly visits than Yahoo.com.
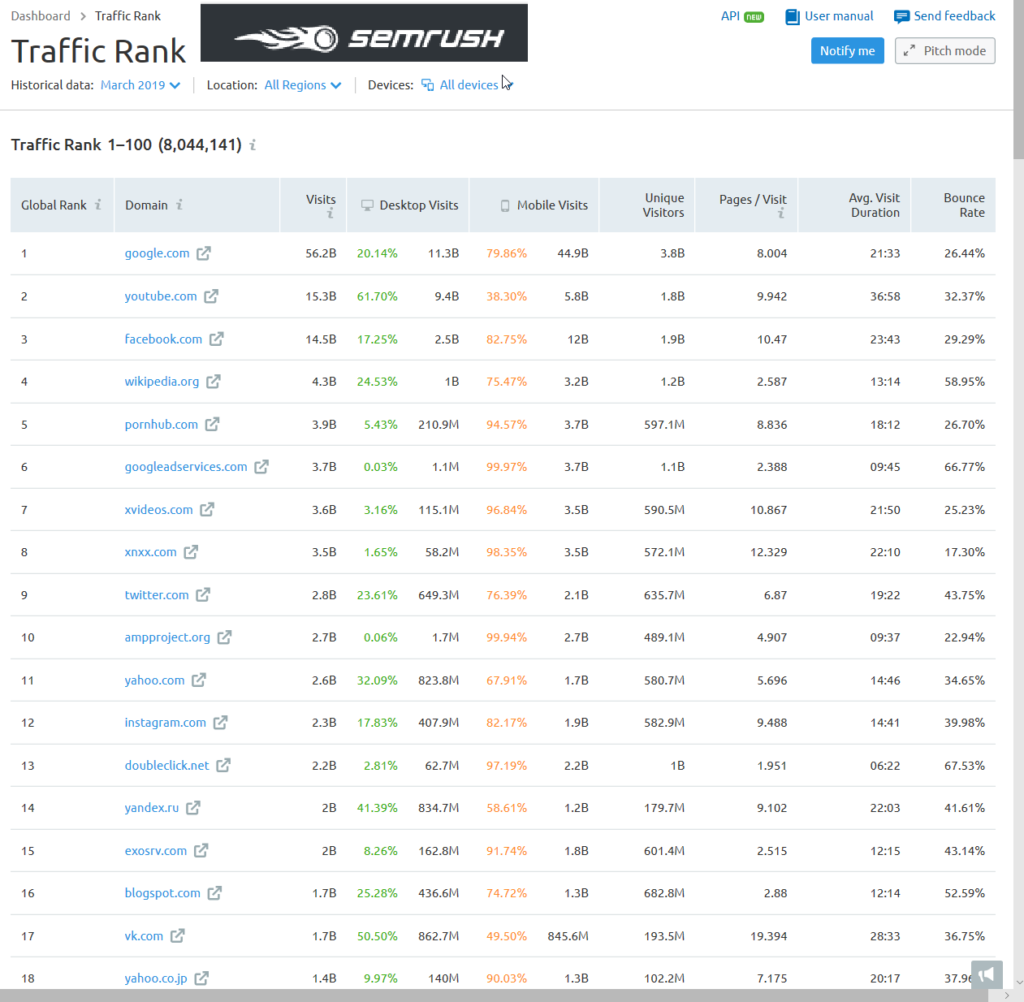
That actually understates the prevalence of AMP because AMP is generally designed for mobile AND not all AMP-formatted content is displayed on ampproject.org.
Part of how AMP was able to get widespread adoption was because in the news vertical the organic search result set was displaced by an AMP block. If you were a news site either you were so differentiated that readers would scroll past the AMP block in the search results to look for you specifically, or you adopted AMP, or you were doomed.
Some news organizations like The Guardian have a team of about a dozen people reformatting their content to the duplicative & proprietary AMP format. That's wasteful, but necessary "In theory, adoption of AMP is voluntary. In reality, publishers that don’t want to see their search traffic evaporate have little choice. New data from publisher analytics firm Chartbeat shows just how much leverage Google has over publishers thanks to its dominant search engine."
It seems more than a bit backward that low margin publishers are doing duplicative work to distance themselves from their own readers while improving the profit margins of monopolies. But it is what it is. And that no doubt drew the ire of many publishers across the EU.
And now there are AMP Stories to eat up even more visual real estate.
If you spent a bunch of money to create a highly differentiated piece of content, why would you prefer that high spend flagship content appear on a third party website rather than your own?
Google & Facebook have done such a fantastic job of eating the entire pie that some are celebrating Amazon as a prospective savior to the publishing industry. That view - IMHO - is rather suspect.
Where any of the tech monopolies dominate they cram down on partners. The New York Times acquired The Wirecutter in Q4 of 2016. In Q1 of 2017 Amazon adjusted their affiliate fee schedule.
Amazon generally treats consumers well, but they have been much harder on business partners with tough pricing negotiations, counterfeit protections, forced ad buying to have a high enough product rank to be able to rank organically, ad displacement of their organic search results below the fold (even for branded search queries), learning suppliers & cutting out the partners, private label products patterned after top sellers, in some cases running pop over ads for the private label products on product level pages where brands already spent money to drive traffic to the page, etc.
They've made things tougher for their partners in a way that mirrors the impact Facebook & Google have had on online publishers:
"Boyce’s experience on Amazon largely echoed what happens in the offline world: competitors entered the market, pushing down prices and making it harder to make a profit. So Boyce adapted. He stopped selling basketball hoops and developed his own line of foosball tables, air hockey tables, bocce ball sets and exercise equipment. The best way to make a decent profit on Amazon was to sell something no one else had and create your own brand. ... Amazon also started selling bocce ball sets that cost $15 less than Boyce’s. He says his products are higher quality, but Amazon gives prominent page space to its generic version and wins the cost-conscious shopper."
Google claims they have no idea how content publishers are with the trade off between themselves & the search engine, but every quarter Alphabet publish the share of ad spend occurring on owned & operated sites versus the share spent across the broader publisher network. And in almost every quarter for over a decade straight that ratio has grown worse for publishers.
The aggregate numbers for news publishers are worse than shown above as Google is ramping up ads in video games quite hard. They've partnered with Unity & promptly took away the ability to block ads from appearing in video games using googleadsenseformobileapps.com exclusion (hello flat thumb misclicks, my name is budget & I am gone!)
They will also track video game player behavior & alter game play to maximize revenues based on machine learning tied to surveillance of the user's account: "We’re bringing a new approach to monetization that combines ads and in-app purchases in one automated solution. Available today, new smart segmentation features in Google AdMob use machine learning to segment your players based on their likelihood to spend on in-app purchases. Ad units with smart segmentation will show ads only to users who are predicted not to spend on in-app purchases. Players who are predicted to spend will see no ads, and can simply continue playing."
And how does the growth of ampproject.org square against the following wisdom?
Literally only yesterday did Google begin supporting instant loading of self-hosted AMP pages.
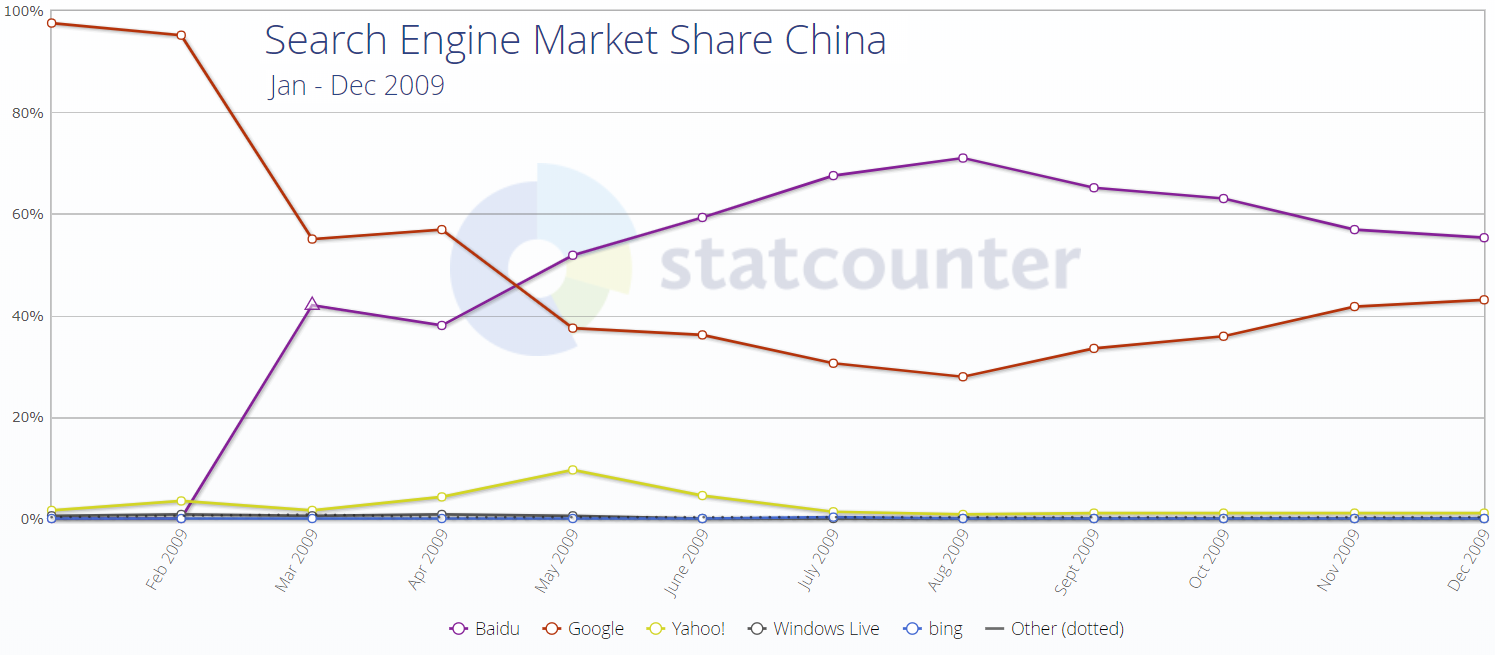
China has a different set of tech leaders than the United States. Baidu, Alibaba, Tencent (BAT) instead of Facebook, Amazon, Apple, Netflix, Google (FANG). China tech companies may have won their domestic markets in part based on superior technology or better knowledge of the local culture, though those same companies have largely went nowhere fast in most foreign markets. A big part of winning was governmental assistance in putting a foot on the scales.
Part of the US-China trade war is about who controls the virtual "seas" upon which value flows:
it can easily be argued that the last 60 years were above all the era of the container-ship (with container-ships getting ever bigger). But will the coming decades still be the age of the container-ship? Possibly not, for the simple reason that things that have value increasingly no longer travel by ship, but instead by fiberoptic cables! ... you could almost argue that ZTE and Huawei have been the “East India Company” of the current imperial cycle. Unsurprisingly, it is these very companies, charged with laying out the “new roads” along which “tomorrow’s value” will flow, that find themselves at the center of the US backlash. ... if the symbol of British domination was the steamship, and the symbol of American strength was the Boeing 747, it seems increasingly clear that the question of the future will be whether tomorrow’s telecom switches and routers are produced by Huawei or Cisco. ... US attempts to take down Huawei and ZTE can be seen as the existing empire’s attempt to prevent the ascent of a new imperial power. With this in mind, I could go a step further and suggest that perhaps the Huawei crisis is this century’s version of Suez crisis. No wonder markets have been falling ever since the arrest of the Huawei CFO. In time, the Suez Crisis was brought to a halt by US threats to destroy the value of sterling. Could we now witness the same for the US dollar?
China maintains Huawei is an employee-owned company. But that proposition is suspect. Broadly stealing technology is vital to the growth of the Chinese economy & they have no incentive to stop unless their leading companies pay a direct cost. Meanwhile, China is investigating Ericsson over licensing technology.
Amazon will soon discontinue selling physical retail products in China: "Amazon shoppers in China will no longer be able to buy goods from third-party merchants in the country, but they still will be able to order from the United States, Britain, Germany and Japan via the firm’s global store. Amazon expects to close fulfillment centers and wind down support for domestic-selling merchants in China in the next 90 days."
India has taken notice of the success of Chinese tech companies & thus began to promote "national champion" company policies. That, in turn, has also meant some of the Chinese-styled laws requiring localized data, antitrust inquiries, foreign ownership restrictions, requirements for platforms to not sell their own goods, promoting limits on data encryption, etc.
The secretary of India’s Telecommunications Department, Aruna Sundararajan, last week told a gathering of Indian startups in a closed-door meeting in the tech hub of Bangalore that the government will introduce a “national champion” policy “very soon” to encourage the rise of Indian companies, according to a person familiar with the matter. She said Indian policy makers had noted the success of China’s internet giants, Alibaba Group Holding Ltd. and Tencent Holdings Ltd. ... Tensions began rising last year, when New Delhi decided to create a clearer set of rules for e-commerce and convened a group of local players to solicit suggestions. Amazon and Flipkart, even though they make up more than half the market, weren’t invited, according to people familiar with the matter.
Amazon vowed to invest $5 billion in India & they have done some remarkable work on logistics there. Walmart acquired Flipkart for $16 billion.
Other emerging markets also have many local ecommerce leaders like Jumia, MercadoLibre, OLX, Gumtree, Takealot, Konga, Kilimall, BidOrBuy, Tokopedia, Bukalapak, Shoppee, Lazada. If you live in the US you may have never heard of *any* of those companies. And if you live in an emerging market you may have never interacted with Amazon or eBay.
It makes sense that ecommerce leadership would be more localized since it requires moving things in the physical economy, dealing with local currencies, managing inventory, shipping goods, etc. whereas information flows are just bits floating on a fiber optic cable.
If the Internet is primarily seen as a communications platform it is easy for people in some emerging markets to think Facebook is the Internet. Free communication with friends and family members is a compelling offer & as the cost of data drops web usage increases.
At the same time, the web is incredibly deflationary. Every free form of entertainment which consumes time is time that is not spent consuming something else.
Add the technological disruption to the wealth polarization that happened in the wake of the great recession, then combine that with algorithms that promote extremist views & it is clearly causing increasing conflict.
If you are a parent and you think you child has no shot at a brighter future than your own life it is easy to be full of rage.
Empathy can radicalize otherwise normal people by giving them a more polarized view of the world:
Starting around 2000, the line starts to slide. More students say it's not their problem to help people in trouble, not their job to see the world from someone else's perspective. By 2009, on all the standard measures, Konrath found, young people on average measure 40 percent less empathetic than my own generation ... The new rule for empathy seems to be: reserve it, not for your "enemies," but for the people you believe are hurt, or you have decided need it the most. Empathy, but just for your own team. And empathizing with the other team? That's practically a taboo.
A complete lack of empathy could allow a psychopath to commit extreme crimes while feeling no guilt, shame or remorse. Extreme empathy can have the same sort of outcome:
"Sometimes we commit atrocities not out of a failure of empathy but rather as a direct consequence of successful, even overly successful, empathy. ... They emphasized that students would learn both sides, and the atrocities committed by one side or the other were always put into context. Students learned this curriculum, but follow-up studies showed that this new generation was more polarized than the one before. ... [Empathy] can be good when it leads to good action, but it can have downsides. For example, if you want the victims to say 'thank you.' You may even want to keep the people you help in that position of inferior victim because it can sustain your feeling of being a hero." - Fritz Breithaupt
News feeds will be read. Villages will be razed. Lynch mobs will become commonplace.
Many people will end up murdered by algorithmically generated empathy.
As technology increases absentee ownership & financial leverage, a society led by morally agnostic algorithms is not going to become more egalitarian.
When politicians throw fuel on the fire it only gets worse:
It’s particularly odd that the government is demanding “accountability and responsibility” from a phone app when some ruling party politicians are busy spreading divisive fake news. How can the government ask WhatsApp to control mobs when those convicted of lynching Muslims have been greeted, garlanded and fed sweets by some of the most progressive and cosmopolitan members of Modi’s council of ministers?
Mark Zuckerburg won't get caught downstream from platform blowback as he spends $20 million a year on his security.
The web is a mirror. Engagement-based algorithms reinforcing our perceptions & identities.
And every important story has at least 2 sides!
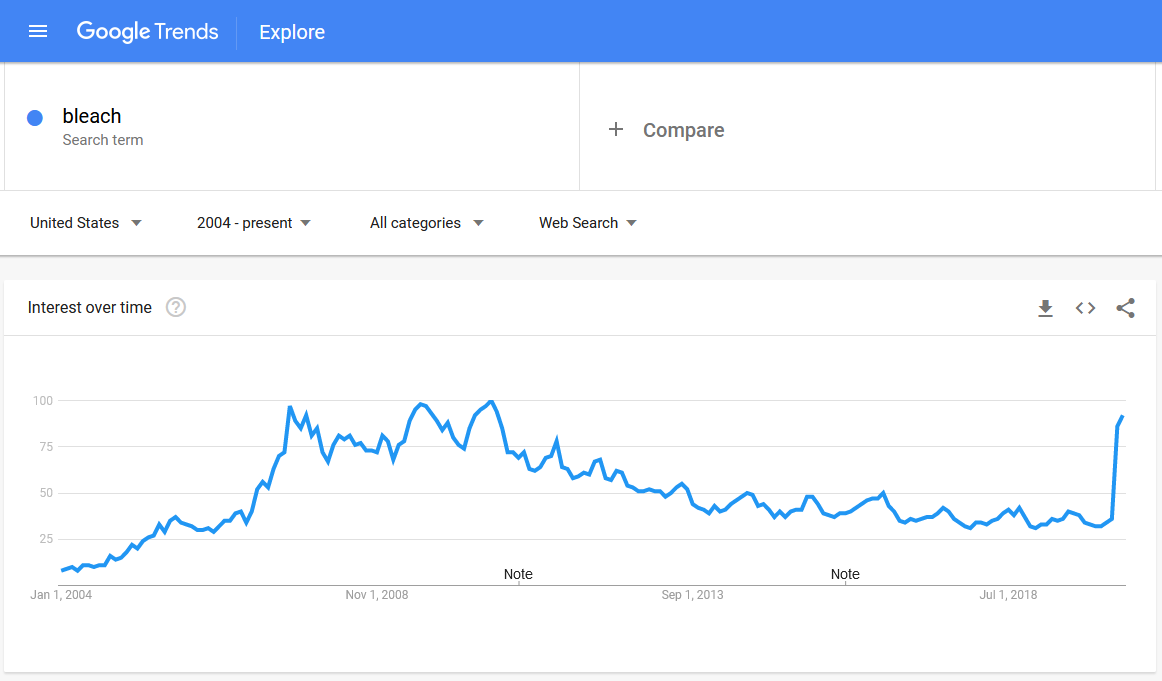
Some may "learn" vaccines don't work. Others may learn the vaccines their own children took did not work, as it failed to protect them from the antivax content spread by Facebook & Google, absorbed by people spreading measles & Medieval diseases.
Passion drives engagement, which drives algorithmic distribution: "There’s an asymmetry of passion at work. Which is to say, there’s very little counter-content to surface because it simply doesn’t occur to regular people (or, in this case, actual medical experts) that there’s a need to produce counter-content."
As the costs of "free" become harder to hide, social media companies which currently sell emerging markets as their next big growth area will end up having embedded regulatory compliance costs which will end up exceeding any sort of prospective revenue they could hope to generate.
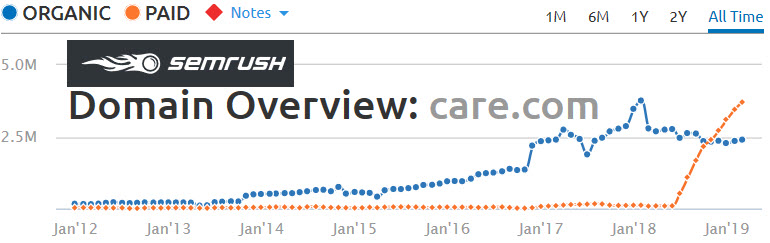
The Pinterest S1 shows almost all their growth is in emerging markets, yet almost all their revenue is inside the United States.
As governments around the world see the real-world cost of the foreign tech companies & view some of them as piggy banks, eventually the likes of Facebook or Google will pull out of a variety of markets they no longer feel worth serving. It will be like Google did in mainland China with search after discovering pervasive hacking of activist Gmail accounts.
Lower friction & lower cost information markets will face more junk fees, hurdles & even some legitimate regulations. Information markets will start to behave more like physical goods markets.
The tech companies presume they will be able to use satellites, drones & balloons to beam in Internet while avoiding messy local issues tied to real world infrastructure, but when a local wealthy player is betting against them they'll probably end up losing those markets: "One of the biggest cheerleaders for the new rules was Reliance Jio, a fast-growing mobile phone company controlled by Mukesh Ambani, India’s richest industrialist. Mr. Ambani, an ally of Mr. Modi, has made no secret of his plans to turn Reliance Jio into an all-purpose information service that offers streaming video and music, messaging, money transfer, online shopping, and home broadband services."
Publishers do not have "their mojo back" because the tech companies have been so good to them, but rather because the tech companies have been so aggressive that they've earned so much blowback which will in turn lead publishers to opting out of future deals, which will eventually lead more people back to the trusted brands of yesterday.
Publishers feeling guilty about taking advertorial money from the tech companies to spread their propaganda will offset its publication with opinion pieces pointing in the other direction: "This is a lobbying campaign in which buying the good opinion of news brands is clearly important. If it was about reaching a target audience, there are plenty of metrics to suggest his words would reach further – at no cost – on Facebook. Similarly, Google is upping its presence in a less obvious manner via assorted media initiatives on both sides of the Atlantic. Its more direct approach to funding journalism seems to have the desired effect of making all media organisations (and indeed many academic institutions) touched by its money slightly less questioning and critical of its motives."
When Facebook goes down direct visits to leading news brand sites go up.
When Google penalizes a no-name me-too site almost nobody realizes it is missing. But if a big publisher opts out of the ecosystem people will notice.
The reliance on the tech platforms is largely a mirage. If enough key players were to opt out at the same time people would quickly reorient their information consumption habits.
If the platforms can change their focus overnight then why can't publishers band together & choose to dump them?
In Europe there is GDPR, which aimed to protect user privacy, but ultimately acted as a tax on innovation by local startups while being a subsidy to the big online ad networks. They also have Article 11 & Article 13, which passed in spite of Google's best efforts on the scaremongering anti-SERP tests, lobbying & propaganda fronts: "Google has sparked criticism by encouraging news publishers participating in its Digital News Initiative to lobby against proposed changes to EU copyright law at a time when the beleaguered sector is increasingly turning to the search giant for help."
Remember the Eric Schmidt comment about how brands are how you sort out (the non-YouTube portion of) the cesspool? As it turns out, he was allegedly wrong as Google claims they have been fighting for the little guy the whole time:
Article 11 could change that principle and require online services to strike commercial deals with publishers to show hyperlinks and short snippets of news. This means that search engines, news aggregators, apps, and platforms would have to put commercial licences in place, and make decisions about which content to include on the basis of those licensing agreements and which to leave out. Effectively, companies like Google will be put in the position of picking winners and losers. ... Why are large influential companies constraining how new and small publishers operate? ... The proposed rules will undoubtedly hurt diversity of voices, with large publishers setting business models for the whole industry. This will not benefit all equally. ... We believe the information we show should be based on quality, not on payment.
Facebook claims there is a local news problem: "Facebook Inc. has been looking to boost its local-news offerings since a 2017 survey showed most of its users were clamoring for more. It has run into a problem: There simply isn’t enough local news in vast swaths of the country. ... more than one in five newspapers have closed in the past decade and a half, leaving half the counties in the nation with just one newspaper, and 200 counties with no newspaper at all."
Google is so for the little guy that for their local news experiments they've partnered with a private equity backed newspaper roll up firm & another newspaper chain which did overpriced acquisitions & is trying to act like a PE firm (trying to not get eaten by the PE firm).
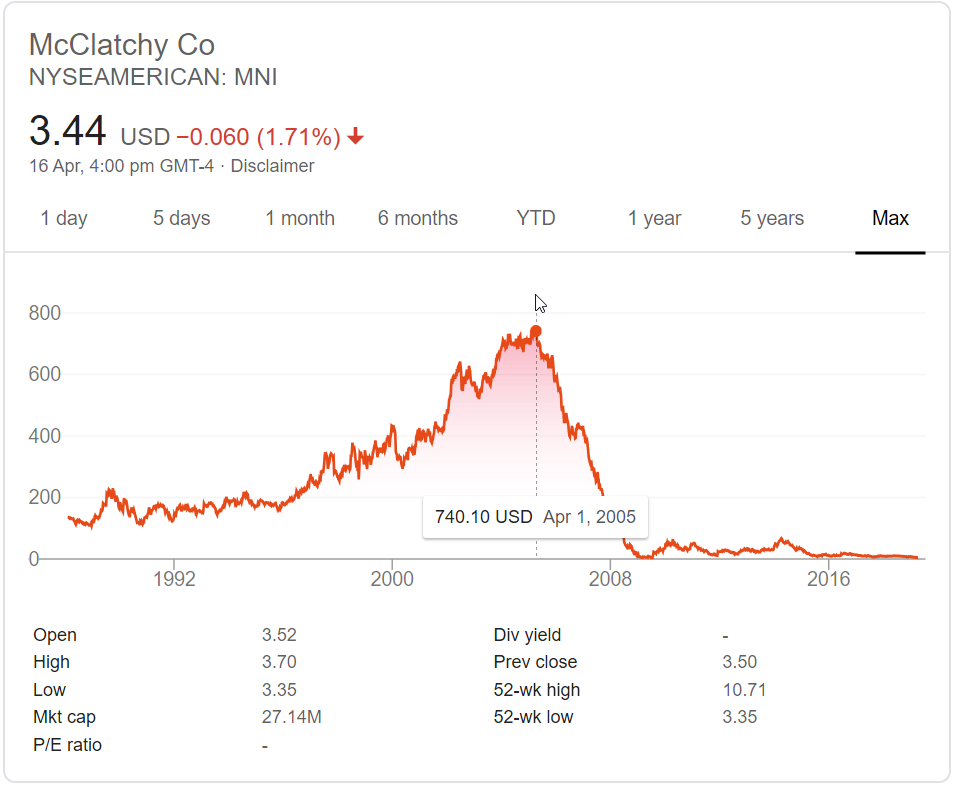
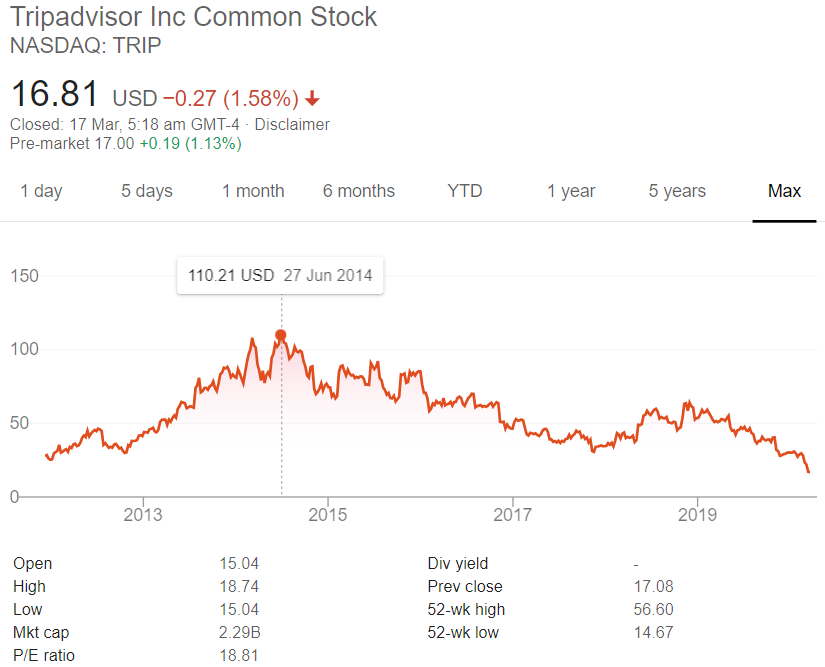
Does the above stock chart look in any way healthy?
Does it give off the scent of a firm that understood the impact of digital & rode it to new heights?
If you want good market-based outcomes, why not partner with journalists directly versus operating through PE chop shops?
If Patch is profitable & Google were a neutral ranking system based on quality, couldn't Google partner with journalists directly?
Throwing a few dollars at a PE firm in some nebulous partnership sure beats the sort of regulations coming out of the EU. And the EU's regulations (and prior link tax attempts) are in addition to the three multi billion Euro fines the European Union has levied against Alphabet for shopping search, Android & AdSense.
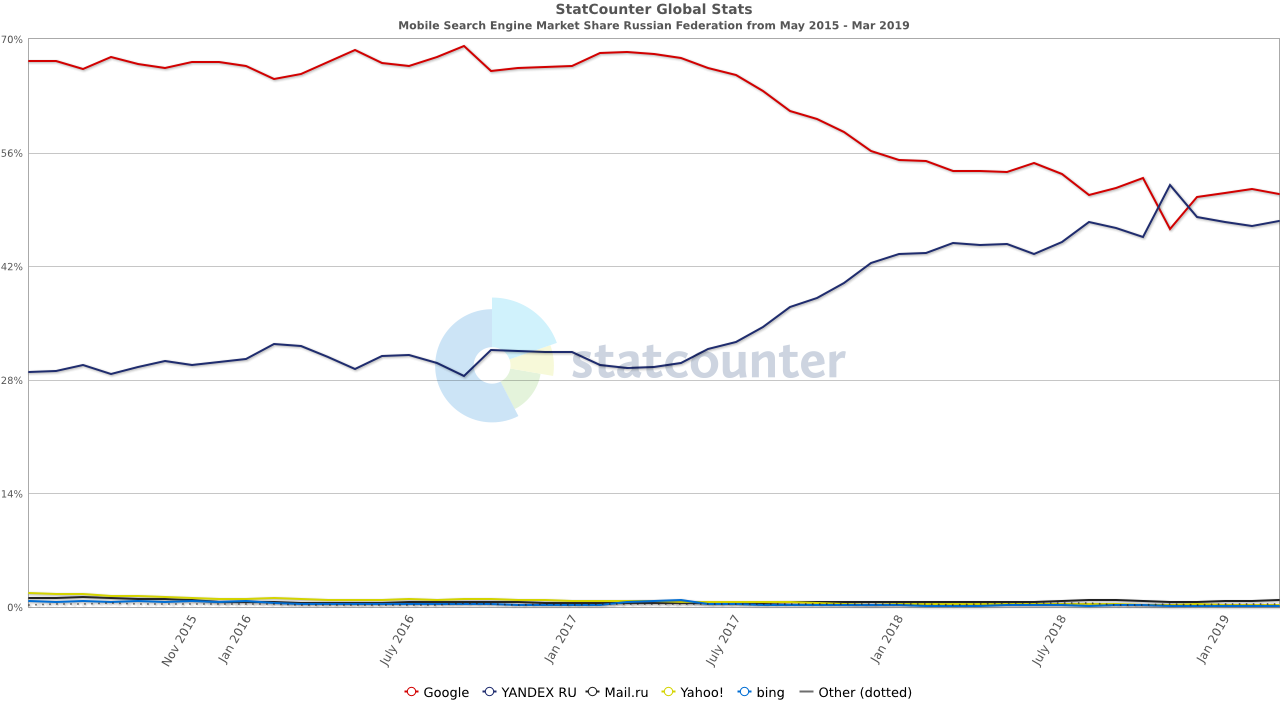
Google was also fined in Russia over Android bundling. The fine was tiny, but after consumers gained a search engine choice screen (much like Google pushed for in Europe on Microsoft years ago) Yandex's share of mobile search grew quickly.
The UK recently published a white paper on online harms. In some ways it is a regulation just like the tech companies might offer to participants in their ecosystems:
Companies will have to fulfil their new legal duties or face the consequences and “will still need to be compliant with the overarching duty of care even where a specific code does not exist, for example assessing and responding to the risk associated with emerging harms or technology”.
If web publishers should monitor inbound links to look for anything suspicious then the big platforms sure as hell have the resources & profit margins to monitor behavior on their own websites.
Australia passed the Sharing of Abhorrent Violent Material bill which requires platforms to expeditiously remove violent videos & notify the Australian police about them.
There are other layers of fracturing going on in the web as well.
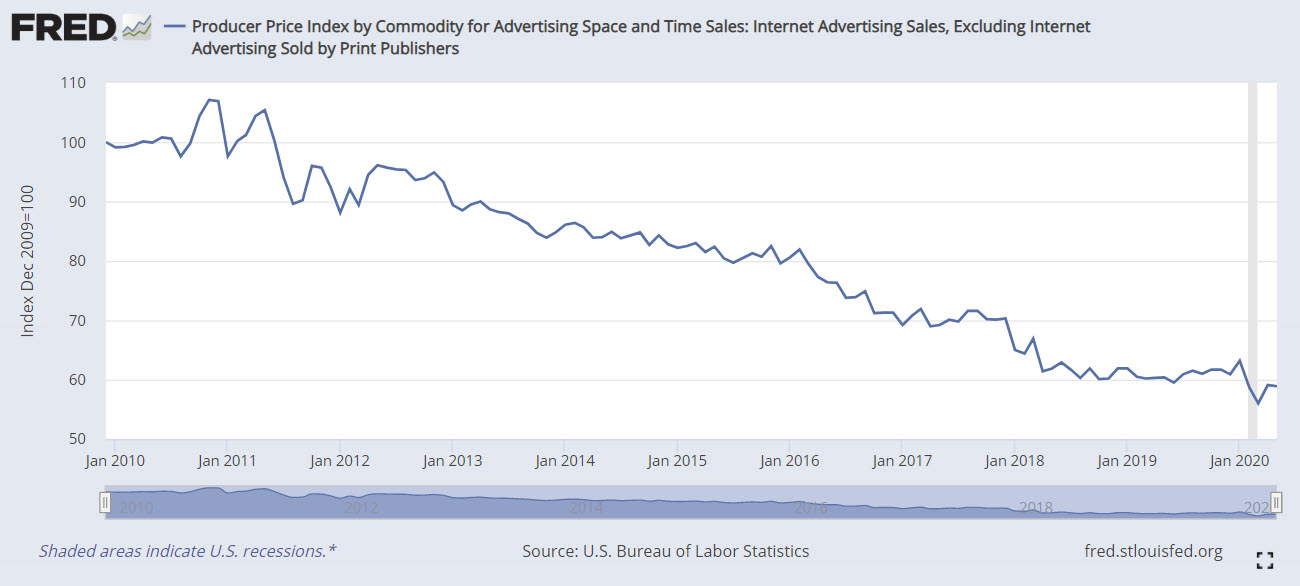
Programmatic advertising shifted revenue from publishers to adtech companies & the largest ad sellers. Ad blockers further lower the ad revenues of many publishers. If you routinely use an ad blocker, try surfing the web for a while without one & you will notice layover welcome AdSense ads on sites as you browse the web - the very type of ad they were allegedly against when promoting AMP.
Tracking protection in browsers & ad blocking features built directly into browsers leave publishers more uncertain. And who even knows who visited an AMP page hosted on a third party server, particularly when things like GDPR are mixed in? Those who lack first party data may end up having to make large acquisitions to stay relevant.
Voice search & personal assistants are now ad channels.
App stores are removing VPNs in China, removing Tiktok in India, and keeping female tracking apps in Saudi Arabia. App stores are centralized chokepoints for governments. Every centralized service is at risk of censorship. Web browsers from key state-connected players can also censor messages spread by developers on platforms like GitHub.
Microsoft's newest Edge web browser is based on Chromium, the source of Google Chrome. While Mozilla Firefox gets most of their revenue from a search deal with Google, Google has still went out of its way to use its services to both promote Chrome with pop overs AND break in competing web browsers:
"All of this is stuff you're allowed to do to compete, of course. But we were still a search partner, so we'd say 'hey what gives?' And every time, they'd say, 'oops. That was accidental. We'll fix it in the next push in 2 weeks.' Over and over. Oops. Another accident. We'll fix it soon. We want the same things. We're on the same team. There were dozens of oopses. Hundreds maybe?" - former Firefox VP Jonathan Nightingale
As phone sales fall & app downloads stall a hardware company like Apple is pushing hard into services while quietly raking in utterly fantastic ad revenues from search & ads in their app store.
Part of the reason people are downloading fewer apps is so many apps require registration as soon as they are opened, or only let a user engage with them for seconds before pushing aggressive upsells. And then many apps which were formerly one-off purchases are becoming subscription plays. As traffic acquisition costs have jumped, many apps must engage in sleight of hand behaviors (free but not really, we are collecting data totally unrelated to the purpose of our app & oops we sold your data, etc.) in order to get the numbers to back out. This in turn causes app stores to slow down app reviews.
Apple acquired the news subscription service Texture & turned it into Apple News Plus. Not only is Apple keeping half the subscription revenues, but soon the service will only work for people using Apple devices, leaving nearly 100,000 other subscribers out in the cold: "if you’re part of the 30% who used Texture to get your favorite magazines digitally on Android or Windows devices, you will soon be out of luck. Only Apple iOS devices will be able to access the 300 magazines available from publishers. At the time of the sale in March 2018 to Apple, Texture had about 240,000 subscribers."
Apple is also going to spend over a half-billion Dollars exclusively licensing independently developed games:
Several people involved in the project’s development say Apple is spending several million dollars each on most of the more than 100 games that have been selected to launch on Arcade, with its total budget likely to exceed $500m. The games service is expected to launch later this year. ... Apple is offering developers an extra incentive if they agree for their game to only be available on Arcade, withholding their release on Google’s Play app store for Android smartphones or other subscription gaming bundles such as Microsoft’s Xbox game pass.
Verizon wants to launch a video game streaming service. It will probably be almost as successful as their Go90 OTT service was. Microsoft is pushing to make Xbox games work on Android devices. Amazon is developing a game streaming service to compliment Twitch.
The hosts on Twitch, some of whom sign up exclusively with the platform in order to gain access to its moneymaking tools, are rewarded for their ability to make a connection with viewers as much as they are for their gaming prowess. Viewers who pay $4.99 a month for a basic subscription — the money is split evenly between the streamers and Twitch — are looking for immediacy and intimacy. While some hosts at YouTube Gaming offer a similar experience, they have struggled to build audiences as large, and as dedicated, as those on Twitch. ... While YouTube has made millionaires out of the creators of popular videos through its advertising program, Twitch’s hosts make money primarily from subscribers and one-off donations or tips. YouTube Gaming has made it possible for viewers to support hosts this way, but paying audiences haven’t materialized at the scale they have on Twitch.
Google, having a bit of Twitch envy, is also launching a video game streaming service which will be deeply integrated into YouTube: "With Stadia, YouTube watchers can press “Play now” at the end of a video, and be brought into the game within 5 seconds. The service provides “instant access” via button or link, just like any other piece of content on the web."
Google will also launch their own game studio making exclusive games for their platform.
When consoles don't use discs or cartridges so they can sell a subscription access to their software library it is hard to be a game retailer! GameStop's stock has been performing like an ICO. And these sorts of announcements from the tech companies have been hitting stock prices for companies like Nintendo & Sony: “There is no doubt this service makes life even more difficult for established platforms,” Amir Anvarzadeh, a market strategist at Asymmetric Advisors Pte, said in a note to clients. “Google will help further fragment the gaming market which is already coming under pressure by big games which have adopted the mobile gaming business model of giving the titles away for free in hope of generating in-game content sales.”
The big tech companies which promoted everything in adjacent markets being free are now erecting paywalls for themselves, balkanizing the web by paying for exclusives to drive their bundled subscriptions.
How many paid movie streaming services will the web have by the end of next year? 20? 50? Does anybody know?
Disney alone with operate Disney+, ESPN+ as well as Hulu.
And then the tech companies are not only licensing exclusives to drive their subscription-based services, but we're going to see more exclusionary policies like YouTube not working on Amazon Echo, Netflix dumping support for Apple's Airplay, or Amazon refusing to sell devices like Chromecast or Apple TV.
The good news in a fractured web is a broader publishing industry that contains many micro markets will have many opportunities embedded in it. A Facebook pivot away from games toward news, or a pivot away from news toward video won't kill third party publishers who have a more diverse traffic profile and more direct revenues. And a regional law blocking porn or gambling websites might lead to an increase in demand for VPNs or free to play points-based games with paid upgrades. Even the rise of metered paywalls will lead to people using more web browsers & more VPNs. Each fracture (good or bad) will create more market edges & ultimately more opportunities. Chinese enforcement of their gambling laws created a real estate boom in Manila.
So long as there are 4 or 5 game stores, 4 or 5 movie streaming sites, etc. ... they have to compete on merit or use money to try to buy exclusives. Either way is better than the old monopoly strategy of take it or leave it ultimatums.
The publisher wins because there is a competitive bid. There won't be an arbitrary 30% tax on everything. So long as there is competition from the open web there will be means to bypass the junk fees & the most successful companies that do so might create their own stores with a lower rate: "Mr. Schachter estimates that Apple and Google could see a hit of about 14% to pretax earnings if they reduced their own app commissions to match Epic’s take."
As the big media companies & big tech companies race to create subscription products they'll spend many billions on exclusives. And they will be training consumers that there's nothing wrong with paying for content. This will eventually lead to hundreds of thousands or even millions of successful niche publications which have incentives better aligned than all the issues the ad supported web has faced.
Added: Facebook pushing privacy & groups is both an attempt to thwart regulation risk while also making their services more relevant to a web that fractures away from a monolithic thing into more niche communities.
One way of looking at Facebook in this moment is as an unstoppable behemoth that bends reality to its will, no matter the consequences. (This is how many journalists tend to see it.) Another way of looking at the company is from the perspective of its fundamental weakness — as a slave to ever-shifting consumer behavior. (This is how employees are more likely to look at it.) ... Zuckerberg’s vision for a new Facebook is perhaps best represented by a coming redesign of the flagship app and desktop site that will emphasize events and groups, at the expense of the News Feed. Collectively, the design changes will push people toward smaller group conversations and real-world meetups — and away from public posts.