So, Google has pulled the chair out from under the SEO industry.
Google is no longer passing (much) keyword referrer data. This has been coming for a while, although many people didn’t expect most keyword data to disappear, and not quite this quickly.
As Aaron noted just last month:
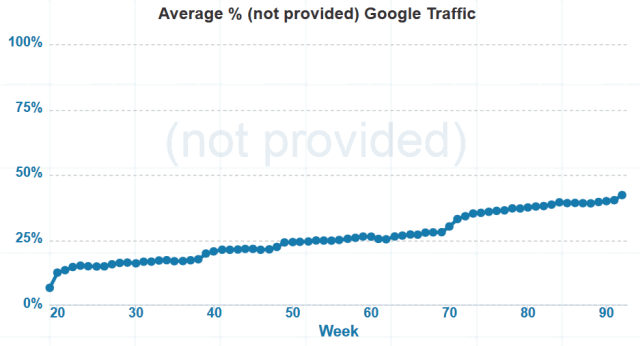
Google is not only hiding half of their own keyword referral data, but they are hiding so much more than half that even when you mix in Bing and Yahoo! you still get over 50% of the total hidden.Google's 86% of the 26,233 searches is 22,560 searches.
Keyword (not provided) being shown for 13,413 is 59% of 22,560. That means Google is hiding at least 59% of the keyword data for organic search. While they are passing a significant share of mobile search referrers, there is still a decent chunk that is not accounted for in the change this past week
Google, citing privacy concerns, has been increasingly withholding keyword data in the form of “not provided”. In the past week, they’ve been pretty on track for 100%, and things look set to stay that way.
In the interests of user privacy.
On yesterday's "This Week in Google," a Google engineer called Matt Cutts revealed that the company started encrypting its queries in 2008 after reading my novel Little Brother
Strangely, privacy doesn’t seem to be an issue when it comes to Adwords. 100% of the keyword referral data remains available via Google’s proprietary advertising channel. I guess the lesson here is that user privacy is much less of an issue, so long as you’re paying Google to see it.
Uh-huh.
Opposite Sides
If anyone is still in any doubt about Google’s relationship with SEOs, then hopefully they’re left in no doubt now. There was no industry consultation, Google unilaterally made these changes and thus broke a search industry standard that has been in place since the search industry began. This move makes life harder for all SEOs.
In terms of privacy issues, there is some truth in it. Problem is, because privacy doesn’t extend to Adwords, the explanation isn’t particularly convincing. The message is that if you want keyword data, then you have to pay to get it via Adwords.
One of the cornerstones of SEO is optimization based on keyword terms. Since last century, SEOs have mined data for keyword terms. They have constructed pages and sites based on those terms with the aim of ranking well for those terms. In theory, everyone wins. The searcher finds what they’re looking for, the search engine looks relevant, and the webmaster receives traffic.
This model has developed some serious cracks over the years.
One problem is PPC. The search engine now has split incentives. They want the results to be relevant, so visitors return often, but, perversely, they also have an incentive for the user not to click on the results, but to click on the advertising links, instead.
This becomes a business problem when an intermediary - an SEO - runs a service that competes with the advertising. The value proposition of the SEO is to get the click on the non-advertising links. Not only is the search engine being deprived of the click, the SEO is likely dissuading, or removing the need, for the site owner spending more on PPC.
So, the SEO is a competitor, although potentially useful in a couple of respects.
One, they encourage sites to be more crawler friendly than they would otherwise be. There was a time when there were a lot of Flash sites, and sites designed, often unwittingly, as uncrawlable brochures. These have mostly been eliminated due to the imperatives of search. SEOs encouraged webmasters to focus more on the production of crawlable content. Secondly, SEOs acted as a defacto-sales force for adwords. If a client saw search as important, then PPC was likely to be part of the mix to help extend reach.
However, as the search engines filled with crawlable content, and a lot of it was junk, the search engines had to get better at determining relevance, and not just by matching keywords. They’ve largely achieved this, so the SEO is no longer offering the search engine much they don’t already now have in abundance - crawlable content they can easily classify.
So, that just leaves the SEO as a competitor and a potential defacto-sales force for a higher Adwords spend. So, removing keyword referral data was a clever move. It will drive more search spend to Adwords and make life harder for Adwords competitors, namely SEOs. If you’re doing Adwords, you’re a customer, if you’re doing SEO, you’re a competitor.
What’s Next?
For some, it will mean a significant change in strategy.
Google don’t need pages optimized against a keyword phrase. In response, SEOs could look at broader page-level metrics, like traffic volumes and conversion rates. They could adopt publishing strategies, backed by sales funnel analytics and optimization. For example, a webmaster may sell a variety of products and spend more time watching out for the on-site links users click on the most in order to determine searcher intent. They optimize what happens after the click. In order to get the click in the first place, they might throw out a fairly wide content net of on-topic pages, and hope to scoop up a lot of fish.
Some will bite the bullet and spend more on Adwords. Adwords will reveal the search keywords linked with volume, and this data can then be fed through into SEO campaigns. We’ll likely see a return to rank checking and matching of these ranks against visitor activity on site.
SEOs could also use proxy information from other search engines, such as Bing. The problem with that other engines have low traffic volumes, meaning comparisons to Google traffic will be inaccurate due to small sample sizes. Still, better than nothing. Webmaster Tools data is available, although this isn’t persistent and is pretty clunky compared to keyword data within analytics packages. No doubt new keyword mining and tracking tools will spring up that will help approximate Google keyword traffic. It will be interesting to see what happens in this space, so if anyone spots any of these services, please add them to the comments.
However, a bigger problem for SEOs still hovers beyond the horizon. If SEOs are competitors to Adwords, then SEOs can expect ongoing changes from Google that will further reduce their ability to compete with Adwords. Another day, another inbound missile. No one should be in any doubt that Google will have a series of missiles lined up.
Vince. Panda. Penguin. Knowledge Graph. Link disavow tool. Decommissioned keyword research tool. Keyword (not provided). More to come.
Adopt A Wider Digital Strategy
One approach is to learn more about the visitor using other metrics at the page and site level.
The point of SEO is to get relevant traffic. Keyword data helped SEOs to target pages and go some way to understanding user intent. However, determining intent by the keyword alone has always been a hit and miss affair. Sometimes, the intent is obvious, particularly on long keyword strings. But the more generic the keyword term, the less you can tell about visitor intent, which then leads to the visitor clicking-back and refining their search.
We should be looking for a richer determination of visitor intent.
Of course, we can watch and measure what visitors do after they arrive on site. If they click back, we know we’re off-topic for that user. Or not attractive enough. Or not getting the message across clearly. Or perhaps we have targeted the wrong demographic. Could the users be segmented a lot further than we already do? We could run A/B testing to learn more about the audience. We could offer multiple paths and see which are the most promising in terms of engagement. If so doing, we understand a lot more about visitors than just guessing based on the keywords they use.
SEOs will likely be looking more at content strategy. Is this content really what the user wants? Is a site offering text when what users really want video? Does the site have a strategy to test content types against one and other? And the placement thereof? We can establish this by gaining a deep understanding of analytics and incorporating demographic information, and other third-party research.
Engagement metrics are a big thing post-Panda. Are people clicking back straight away, or clicking further into the site? Refine content and links until bounce rates come down. These elements can also be tested on Adwords landing pages. If the engagement metrics are right on an adwords landing page, they are likely right if a similar page is used for SEO. The ranking for an individual keyword doesn’t matter so much, just as long as enough of the audience who do arrive are engaging.
Look at optimizing the user experience in terms of better usability and watching the paths they take through the site. Where are we losing people? Could the funnels be made more evident? And which users are we talking about? i.e. young visitors vs old visitors, returning visitor vs new visitors?
There are some high end tools that can help with this, such as Foresters Technographics and Adobe Neolane, however there are other more-than-adequate approaches, mixing readily available tools with a little best practice. Consider website surveys and polls, and third-party profiling tools, like SEMRush, to quantify your competition.
In "Digital Marketing Analytics: Making Sense Of Consumer Data In A Digital World", the authors give a lot of practical advice on mining the various channels so as to better understand your customer, and configure your website to meet their needs. Only a small fraction of this can be gleaned from keyword data.
For example, mining social media channels tells you a lot about your potential audience. How they talk, who they talk to, what their interests are, who they are connected to, where they are, who influences who, and who shares what with who. Social profile and activity analysis offers rich audience insight, often more so than keywords. You can segment and understand your audiences in ways that would be difficult to do using keywords alone.
So, losing keywords makes life difficult. But it also present opportunities.
As Much As Things Change, They Stay The Same
The promise of search marketing is to deliver the right message to the right people at the right time. That’s the same promise for all digital marketing, keyword driven or otherwise. We should place just as much emphasis, if not more, on measuring audience behaviour over time i.e. what happens well before the click, and what happens after it, as we do on the keyword, itself.
The better we understand the audience, the better we are able to serve their needs, which likely leads to a more profitable business that those who understand less. Keywords help, but they’re not the be-all and end-all. Google still has the exact same user base. Someone still has to rank #1 against a given keyword term. So long as you're doing Adwords, your competitors have no better idea regarding keywords than you do, so the playing field is still level in that respect.
Those putting more effort into page-level metrics, site metrics, and brand in order to better understand visitors now stand to gain advantage. The fundamentals haven't changed:
- Who is the audience?
- Where are they located?
- What does the audience know?
- What are they interested in?
- What do the audience need?
When SEO becomes harder, the barrier is raised, meaning those who jump that barrier are in a more dependable position than they were before. Remember, most of you will have archived keyword data. New entrants to the SEO field will not, and will find it very difficult, if not impossible, to acquire.
The game just got harder. For everyone.