Microsoft Search BrowseRank Research Reviewed
cNet recently covered a new Microsoft Search research paper on BrowseRank [PDF]. The theory behind the concept of BrowseRank is that rather than using links (PageRank) as the backbone of a relevancy algorithm, you could look at actual usage data from hundreds of millions of users.
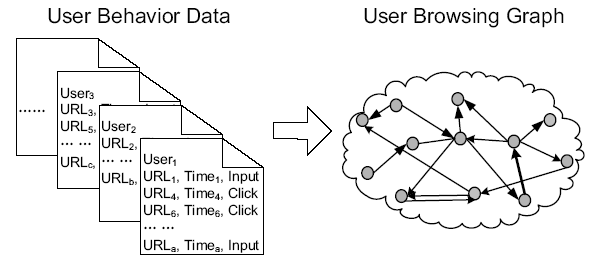
Since there are more web users than webmasters BrowseRank would be a more democratic system, but many users are mislead and/or easily influenced by social media, public relations, and some referral spam strategies, so BrowseRank could surface some low quality temporal information, making manipulating Digg and other "firehose of traffic" sources more valuable than they perhaps should be. Although if certain referrals were blocked (Digg, StumbleUpon, etc.) and/or BrowseRank was combined with a blended search strategy (like how Google mixes Google News in their organic results) Microsoft could have a bit more confidence in waiting out some traffic spikes to see if traffic is sustained. And this potential shortfall (if managed properly) could actually lead to a major advantage over the stale effect of PageRank. If you create non-resource hyped up piece of linkbait that gets a quick rush of links and never gains any more votes then why should that page have a lot of authority to pass around your site?
BrowseRank can look at user time on site to help determine if the site was of quality, and perhaps even normalize for page length, but what happens if a page is really good at answering a common question? Even if people only ask it once in a great while quality content should not be penalized for great formatting, ease of use, and a great user experience - though as search evolves search engines will keep displaying more content in the search results, license specialized data, and answer many common questions directly in the search results.
In addition to looking at traffic that comes via links, BrowseRank also identifies direct URL visits via bookmarks or typing in URLs. These types of traffic sources
are considered "green traffic" because the pages visited in this way are safe, interesting, and/or important for users.
Such an algorithm would add value to direct navigation keyword rich URLs. Another obvious extension of such an algorithm would be identifying brand specific searches and URL searches, and bucketing those referrals into the green category as well.
To encourage such branded search queries and long user interactions it would be better to create strong communities with repeat visitors and many web based tools rather than allowing useful user interactions occur through browser extensions.
Another big issue with BrowseRank is that it highlights many social media sites. The issue with social media is that any piece of content is generally only relevant to a small number of people and most of the content is irrelevant to the population at large. Unless the search engine had a lot of personalized data promoting the general purpose social media sites would be blunderous - surfacing lots of results that are irrelevant, spam, or both.
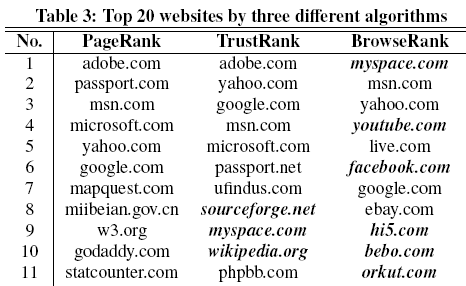
One of the big advantages PageRank has over BrowseRank is an economic one.
- People are more likely to link at informational resources, thus surfacing those pages and sites higher in the search results.
- This gives Google's organic search results an informational bias which makes searchers more likely to click on Google's paid ads when performing a commercial search.
- Google also has the ability to arbitrarily police links and/or strip PageRank scores to 0 with the intent to fearmonger and add opportunity cost to anyone who gathers enough links pointing at a (non-corporate owned) commercial domain. This layer of social engineering coerces publishers to create the type of content Google likes to rank.


Comments
Assuming that all of the problems you highlighted were "fixed" then Microsoft would just end up with a bunch of results that generally mirror Google's. The job of a search engine is to direct people to relevancy. It is not to show them were everyone else has already been (a feedback loop based on flawed logic, as I see it.)
I think that is a hard part of search...it is easy for search to be lazy and heavily rely on lots of user votes before showing new sites and information.
In the current market Yahoo! is slow to rank new sites for new queries and Google requires a decent amount of site age and/or PageRank to rank a site for competitive queries.
I think Microsoft might feel that using fellow searchers as editors might be more effective than relying on the link graph as it has already been done. But like you said, if Google has 70% marketshare, they are going to be showing a lot of Google's results.
I think you name some realistic problems. But I think Google uses browser data a lot as well. With all the data they collect with the Google Toolbar, Google Analytics, iGoogle, etc. Google's already using browse data in their rankings.
I think a combination of analyzing links and browse data could be a winning combination.
Nice and easy to read Aaron, well done!
The new searchengine that is designed by ex. Google emplyees and have more indexed pages than Google, or so they say.
I was surprised to not find any info on this blog about www.cuil.com, pronounced [COOL], that for sure need more server capacity and a ton of money to brand their engine, but if they are as good as they say they are, it will be interesting to follow their progress.
They are more focused on content, which is good for us SEO specialists, but I would love to hear a review from you Aaron on www.cuil.com!
Is it just yet another Google contestant that will get no traction, just another one that will come and go, is it a company we want to follow and buy stocks in - if they go public?
I think they are too new to review...lots of major relevancy issues with them still.
Add new comment