Spam vs Mahalo: Matt Cutts Explains the Difference
When the internal Google remote quality rater guidelines leaked online there was a core quote inside it that defined the essence of spam:
Final Notes on Spam When trying to decide if a page is Spam, it is helpful to ask yourself this question: if I remove the scraped (copied) content, the ads, and the links to other pages, is there anything of value left? if the answer is no, the page is probably Spam.
With the above quote in mind please review the typical Mahalo page
Adding a bit more context, the following 25 minute video from 2008 starts off with Matt Cutts talking about how he penalized a website for using deceptive marketing. Later into the video (~ 21 minutes in) the topic of search results within search results and then Mahalo come up.
Here is a transcription of relevant bits...
Matt Cutts: Would a user be annoyed if they land on this page, right. Because if users get annoyed, if users complain, then that is when we start to take action.
And so it is definitely the case where we have seen search results where a search engine didn't robots.txt something out, or somebody takes a cookie cutter affiliate feed, they just warm it up and slap it out, there is no value add, there is no original content there and they say search results or some comparison shopping sites don't put a lot of work into making it a useful site. They don't add value.
Though we mainly wanted to get on record and say that hey we are willing to take these out, because we try to document everything as much as we can, because if we came and said oh removed some stuff but it wasn't in our guidelines to do that then that would be sub-optimal.
So there are 2 parts to Google's guidelines. There are technical guidelines and quality guidelines. The quality guidelines are things where if you put hidden text we'll consider that spam and we can remove your page. The technical guidelines are more like just suggestions.
...
So we said don't have search results in search results. And if we find those then we may end up pruning those out.
We just want to make sure that searchers get good search results and that they don't just say oh well I clicked on this and I am supposed to find the answer, and now I have to click somewhere else and I am lost, and I didn't find what I wanted. Now I am angry and I am going to complain to Google.
Danny Sulivan: "Mahalo is nothing but search results. I mean that is explicitly what he says he is doing. I will let you qualify it, but if you ask him what it is still to this day he will say its a search engine. And then all the SEOs go 'well if it is a search engine, shouldn't you be blocking all your search results from Google' and his response is 'yeah well IF we ever see them do anything then we might do it'."
Matt Cutts: It's kinda interesting because I think Jason...he is a smart guy. He's a savvy guy, and he threaded the needle where whenever he talked to some people he called it a search service or search engine, and whenever he talked to other people he would say oh it is more of a content play.
And in my opinion, I talked to him, and so I said what software do you use to power your search engine? And he said we use Twika or MediaWiki. You know, wiki software, not C++ not Perl not Python. And at that point it really does move more into a content play. And so it is closer to an About.com than to a Powerset or a Microsoft or Yahoo! Search.
And if you think about it he has even moved more recently to say 'you know, you need to have this much content on the page.' So I think various people have stated how skilled he is at baiting people, but I don't think anybody is going to make a strong claim that it is pure search or that even he seems to be moving away from ok we are nothing but a search engine and moving more toward we have got a lot of people who are paid editors to add a lot of value.
One quick thing to note about the above video was how the site mentioned off the start got penalized for lying for links, and yet Jason Calacanis apologized for getting a reporter fired after lying about having early access to the iPad. Further notice how Matt considered that the first person was lying and deserved to be penalized for it, whereas when he spoke of Jason he used the words savvy, smart, and the line threaded the needle. To the layperson, what is the difference between being a savvy person threading the needle and a habitual liar?
Further lets look at some other surrounding facts in 2010, shall we?
- How does Jason stating "Mahalo sold $250k+ in Amazon product in 2009 without trying" square with Matt Cutts saying "somebody takes a cookie cutter affiliate feed, they just warm it up and slap it out, there is no value add, there is no original content there" ... Does the phrase without trying sound like value add to you? Doesn't to me.
- Matt stated that they do not want searchers to think "oh well I clicked on this and I am supposed to find the answer, and now I have to click somewhere else and I am lost" ... well how does Mahalo intentionally indexing hundreds of thousands of 100% auto-generated pages which simply recycle search results and heavily wrap them in ads square with that? sounds like deceptive & confusing arbitrage to me.
- Matt stated "and if you think about it he has even moved more recently to say 'you know, you need to have this much content on the page,'" but in reality, that was a response to when I highlighted how Mahalo was scraping content. Jason dismissed the incident as an "experimental" page that they would nofollow. Years later, of course, it turned out he was (once again) lying and still doing the same thing, only with far greater scale. Jason once again made Matt Cutts look bad for trusting him.
- Matt stated "I don't think anybody is going to make a strong claim that it is pure search" ... and no, its not pure search. If anything it is IMPURE search, where they use 3rd party content *without permission* and put most of it below the fold, while the Google AdSense ads are displayed front and center.
- If you want to opt out of Mahalo scraping your content you can't because he scrapes it from 3rd party sites and provides NO WAY for you to opt out of him displaying scraped content from your site as content on his page).
- Jason offers an "embed this" option for their content, so you can embed their "content" on your site. But if you use that code the content is in an iframe so it doesn't harm them on the duplicate content front AND the code gives Jason multiple direct clean backlinks. Whereas when Jason automatically embeds millions of scraped listings of your content he puts it right in the page as content on his page AND slaps nofollow on the link. If you use his content he gets credit...when he uses your content you get a lump of coal. NICE!
- And, if you were giving Jason the benefit of the doubt, and thought the above was accidental, check out how when he scrapes the content in that all external links have a nofollow added, but any internal link *does not*
- Matt stated "[Jason is] moving more toward we have got a lot of people who are paid editors to add a lot of value" ... and, in reality, Jason used the recession as an excuse to can the in house editorial team and outsource that to freelancers (which are paid FAR LESS than the amounts he hypes publicly). Given that many of the pages that have original content on them only have 2 sentences surrounded by large swaths of scraped content, I am not sure there is an attempt to "add a lot of value." Do you find this page on Shake and Bake meth to be a high quality editorial page?
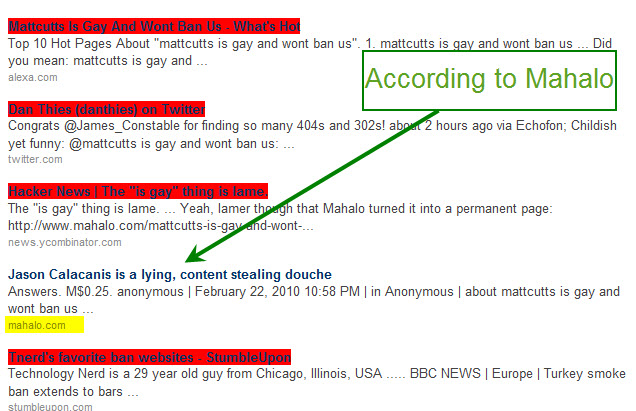
- What is EVEN MORE OUTRAGEOUS when they claim to have some editorial control over the content is that not only do they wrap outbound links which they are scraping content from in nofollow, but they publish articles on topics like 13 YEAR OLD RAPE. Either they have no editorial, or some of the editorial is done by pedophiles.
- Worse yet, such pages are not a rare isolated incident. Michael VanDeMar found out that Mahalo is submitting daily lists of thousands of those auto-generated articles to Google via an XML sitemap...so when Jason claims the indexing was an accident, you know he lied once again!
Here Jason is creating a new auto-generated page about me! And if I want to opt out of being scraped I CAN'T. What other source automatically scrapes content, republishes it wrapped in ads and calls it fair use, and then does not allow you to opt out? What is worse in the below example, is that on that page Jason stole the meta description from my site and used it as his page's meta description (without my permission, and without a way for me to opt out of it).
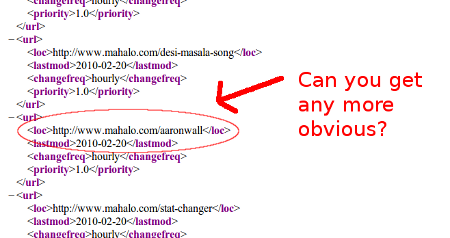
So basically Matt...until you do something, Jason is going to keep spamming the crap out of Google. Each day you ignore him another entreprenuer will follow suit trying to build another company that scrapes off the backs of original content creators. Should Google be paying people to *borrow* 3rd party content without permission (and with no option of opting out)?
I think Jason has pressed his luck and made Matt look naive and stupid. Matt Cutts has got to be pissed. But unfortunately for Matt, Mahalo is too powerful for him to do anything about it. In that spirit, David Naylor recently linked to this page on Twitter.
What is the moral of the story for Jason Calacanas & other SEOs?
- If you are going to create a thin spam site you need to claim to be anti-spam to legitimize it. Never claim to be an SEO publicly, even if you are trying to sell corporate SEO services.
- If you have venture capital and have media access and lie to the media for years it is fine. If you are branded as an SEO and you are caught lying once then no soup for you.
- If you are going to steal third party content and use it as content on your site and try to claim it is fair use make sure you provide a way of opting out (doing otherwise is at best classless, but likely illegal as well).
- If you have venture capital and are good at public relations then Google's quality guidelines simply do not apply to you. Follow Jason's lead as long as Google permits mass autogenerated spam wrapped in AdSense to rank well in their search results.
- The Google Webmaster Guidelines are an arbitrary device used to oppress the small and weak, but do not apply to large Google ad partners.
- Don't waste any of your time reporting search spam or link buying. The above FLAGRANT massive violation of Google's guidelines was reported on SearchEngineLand, and yet the issue continues without remedy - showing what a waste of time it is to highlight such issues to Google.


{kind=link}
{kind=link}
{kind=link}
Comments
I think the most relevant point is
"The Google Webmaster Guidelines are an arbitrary device used to oppress the small and weak, but do not apply to large Google ad partners."
Especially now that Google answers to it's shareholders, sites that are generating good ad revenue are going to get a pass on the quality guidelines be they as large as Mahalo or smaller MFA sites that add no value. The only thing I see stopping this is the general public getting so fed up with crappy results that they vote with their feet (or their mouse) and go elsewhere. It doesn't matter to Google what a few SEOs think, as long as the masses keep clicking those ads.
Ouch
Nice graphic, Aaron... although I might quibble about your definition of "content" a bit - because the part you labeled as content ("hazara.com") is also just scraped from the feed.
Mahalo has gone from being just another crappy screen scraper to probably the worst example of spam in Google's index.
Of course, Google's getting some revenue from it, aren't they?
Aaron,
Perhaps those of us who have had our content scraped w/o permission should unite and form a class-action law suit to settle the matter. He's violated laws, not just seo boundaries and should pay the penalty.
Thoughts?
~jason (not calcanis)
Matt Cutt's runs the quality team not Google. Clearly Jason Calcanis is working connections above Matt's level, and successfully keeping the quality team blind to his violations. We all know that's Jason's "style" anyway, plus he's clearly a self-admitted liar and Matt is not. No competition, right?
@Serpsleuth - that's a valid point. For all we know, Matt's hands (and that of his team) were tied a long time ago.
...Waiting for Jason's overtly humble response comment:
"Aaron: Thank you so much for helping us improve our site.
You've helped us so much with SEO and we credit you personally with building mahalo into what it is today.
You see Aaron, because you've contributed so much sage advice to us, you can basically take credit for all of this.
All the best, and come visit us soon!"
Funny Matt, Mahalo's slogan is, "Human-Powered Search" not "Human Powered Content Play."
And its not called a "machine scraped content play". ;)
Is'nt their slogan "we are here to help?"
Perhaps "we are here to help" ... get your content scraped and wrapped in AdSense ads. Thanks for the free content, fools. :D
I have seen Matt comment on things you say when they have no bearing on how Google might be perceived.
His lack of comments here says just as much to me, and it is a shame. His reputation is built on confronting sticky issues, but you and Danny left no holes in the argument, and Matt is nowhere to be seen.
Talk about something useless, like nofollow, and he'll chime in accordingly.
C'mon Matt - I am counting on you here.
Aaron: It’s not Spam, It’s a “Newsmaster Site”
Haha...love that post QuadsZilla :D
Newsmaster is such a sweet name!
I couldn't agree more. Jason is a complete douche-bag and Matt Cutts needs to stop being a b-tch.
Google doesn't care because...
1) Google is a business built around stealing other people's content and placing their ads around it. Google does it, youtube does it, Google book search does it. etc...
2) Mahalo uses google adsense, so Google makes money when they steal other people's content and puts adsense ads around it!
3) google IS evil.
Thanks for the continuing education Aaron, not only wont Mahalo allow optout when they scrape your content or metatags, but it appears that they also wont allow optout if you have signed up as a member on their site. Since reading your posts over the last while I have tried to have my membership removed/cancelled. All requests to Mahalo have been totally ignored along with any links to social networks which don't seem to work properly on their site??? Obviously this part of their site is dysfunctional & I am pissed off that I cannot free myself from Mahalo & their dreadful reputation.
I had to unsubscribe from Jason's email newsletter. The condescending piety in it was sickening.
Google will never slap the hand of those who make them money. Jason knows this.
They slap the hand of those that make them money all the time. Typically it's smaller affiliates and scrapers. I don't think their support of Mahalo is financial as it's still such a small amount of money in their world. I'd argue that they seem scared of the people behind Mahalo for some reason. Odd that you'd see that out of a mega-billion dollar company.
I guess I just don't understand what the big deal is - Mahalo is weak and Google never applies the same rules for all sites. I've seen it several times, Mahalo is just one of the many exceptions.
In my industry, a user can search for a new home community e.g. Crestview At Stoneybrook Hills, and they'll find the exact same information on at least 10 of the first 20 results. Same information from the same db - it's silly.
If you do a little research, you'll find that most of those 10 pages (sub domains) can't be found outside of using Google - they're mostly on local newspaper website's with authority domains i.e. al.com, but if you're on al.com you can't find the same information anywhere.
The company that owns the information knows exactly what they're doing and dominates the industry. They link back to their network of sites from each authority domain; I can't blame them. I can't blame Mahalo either, I think they're silly, but if they can manipulate the system, make a killing for doing it, and get away with it, why stop doing it?
Needless to say, Google punishes smaller sites for doing less, often. At the end of the day it's all about money and brand strength. These sites make Google money and help build Google's brand, they also have strong brands themselves.
Google's a great company and I love most, if not all of their products, but they certainly help evil companies stay evil.
Insightful, accurate, and hilarious!
Well it does look like Matt Cutts has commented, albeit in a off handed manner, on the Mahalo topic.
http://www.mattcutts.com/blog/calling-for-link-spam-reports/?utm_source=...
What a total load of B/S.
I just posted this in response
"We’ve deleted or noindexed almost every single short content page. These pages were about 6% of our traffic. We filled out the content on the top 5% of these pages and they have actually ranked better in a non-scientific survey (score one for “more original content = better SEO”). Our net traffic loss looks like 1-2% or maybe even after getting rid of these short pages.
As far as the “scraping” claim I think Aaron is confusing caching, which we do, with scraping (which we don’t). If you want to de-index from mahalo simply email contact@mahalo.com and we will make it happen.
Thanks to Aaron for the feedback. We never wanted to get credit for low content pages and we should have been more on top of this issue. We are no very much on top of it and we’ve set our baseline for pages at 300 original words. Our thousands of active contributors are actually doing that as we speak.
We’re an original content site like Wikipedia or Yahoo Answers with a little search added. So, Matt is right we are a content site first (i’d say content and community).
We have thousands of salt of the earth people earning their car payment, kids school clothes or rent building high-quality content pages at Mahalo. Please don’t take out my stupid statements about SEO from six years ago against them.
We are good people trying to do good work even if we make a mistake once and a while.
again, thanks… Jason"
What about a tag that can be included on pages with original, copyrightable content? Once such pages are manually submitted to the engines, spiders can quickly ascertain if the content is unique and then keep record... any "too similar" copies of that content that become visible to spiders after that date are simply not indexed. Just an idea. Also isn't it about time the search engines started to work together with multimedia creators on a form of search engine recognizable watermarking for original content?
Some folks would steal 3rd party content & then label themselves as the original source (and try to feed it into Google first).
Google is already great at watermarking content for Youtube...but they have less incentive to do it with textual content because...
Add new comment