Robots.txt vs Rel=Nofollow vs Meta Robots Nofollow
I was just fixing up our Robots.txt tutorial today, and figured that I should blog this as well. From Eric Enge's interview of Matt Cutts I created the following chart. Please note that Matt did not say they are more likely to ban you for using rel=nofollow, but they have on multiple occasions stated that they treat issues differently if they think it was an accident done by an ignorant person or a malicious attempt to spam their search engine by a known SEO (in language that is more rosy than what I just wrote).
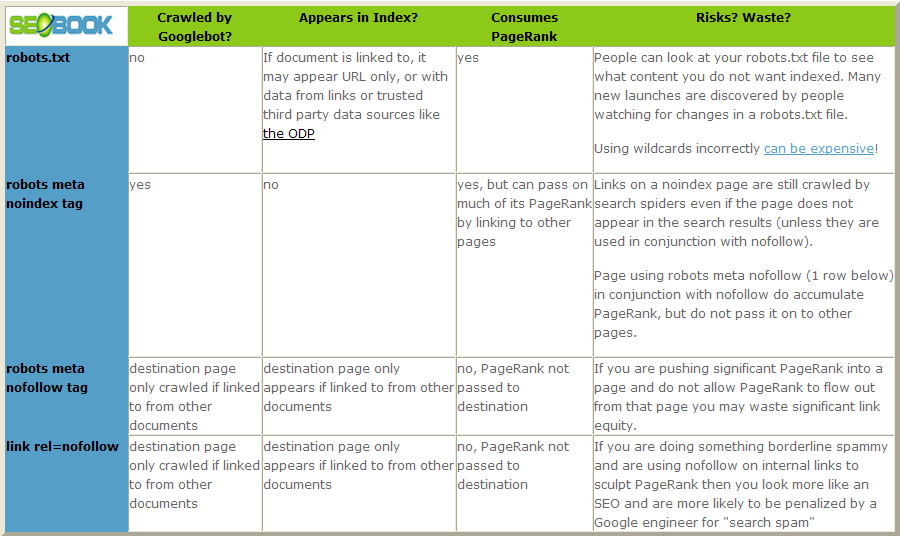
 |
Crawled by Googlebot? |
Appears in Index? |
Consumes PageRank |
Risks? Waste? |
| robots.txt | no | If document is linked to, it may appear URL only, or with data from links or trusted third party data sources like the ODP | yes | People can look at your robots.txt file to see what content you do not want indexed. Many new launches are discovered by people watching for changes in a robots.txt file. Using wildcards incorrectly can be expensive! |
| robots meta noindex tag | yes | no | yes, but can pass on much of its PageRank by linking to other pages | Links on a noindex page are still crawled by search spiders even if the page does not appear in the search results (unless they are used in conjunction with nofollow on that page). Page using robots meta nofollow (1 row below) in conjunction with noindex do accumulate PageRank, but do not pass it on to other pages. |
| robots meta nofollow tag | destination page only crawled if linked to from other documents | destination page only appears if linked to from other documents | no, PageRank not passed to destination | If you are pushing significant PageRank into a page and do not allow PageRank to flow out from that page you may waste significant link equity. |
| link rel=nofollow | destination page only crawled if linked to from other documents | destination page only appears if linked to from other documents | no, PageRank not passed to destination | If you are doing something borderline spammy and are using nofollow on internal links to sculpt PageRank then you look more like an SEO and are more likely to be penalized by a Google engineer for "search spam" |
If you want to download the chart as an image here you go http://www.seobook.com/images/robotstxtgrid.png


{kind=link}
Comments
So what would be the best way to sculpt your pagerank then if you need those links on the page?
rel=nofollow on the link itself...all the other techniques have you spending PageRank on the pages you do not want indexed.
So is it officially bad to use rel nofollow to sculpt internal page rank? I wish there was more clarity on this!
It is NOT officially bad to use rel nofollow on links, but if you are already fairly aggressive with your SEO then using it confirms that you probably know SEO, and thus they are more likely to police you more closely.
What would you regard aggressive SEO? Would that be more to do with what practices you're doing or the volume of practices you're carrying out.
You are sorta asking me if I know what the limits are inside of Matt's head and how they might change over time. I can't answer that though, which is why I caution against using rel=nofollow on internal links for PageRank sculpting unless the site is fairly clean.
Thanks for your feedback, Aaron. It'd be good to see a post on sites (from big to small) that use it or about any nofollow casualties.
"So is it officially bad to use rel nofollow to sculpt internal page rank?"
No, Google can't afford people to think that using rel=nofollow is a negative quality signal. Matt Cutts also clearly said there's no stigma attached to using rel=nofollow. Rel=nofollows basically are not much different from using META ROBOTS or robots.txt - all of those tools control crawling and in some cases PageRank flow. I wouldn't say robots.txt is a negative quality signal. I also don't think Google considers site owners that nofollows paid link spammers, nor site owners that followed Google's own advice by nofollowing links to login pages.
Too many SEOs turn opinion, suspicion, and 80% likelihood of X happening into fact. There's no proof rel=nofollow will mark you as a spammer (yet). There's a chance that Googlers secretively use nofollows to smoke out spammers, but we don't know how big of a chance that is, so any risk factor we associate with it is nothing more than a wild guess.
I didn't say that using nofollow makes you seem like a spammer...I stated that using rel=nofollow in conjunction with "doing things that are borderline spammy" could make Google more likely to whack your site. why? when you use rel=nofollow to sculpt PageRank you lose plausible deniability that you didn't know what you were doing.
After all, Google's guidelines are not absolutes, but are intent based. If you label yourself as an SEO (which using rel=nofollow to sculpt PageRank does) you put yourself in a special group that may be looked at a bit differently when they are reviewing other aspects of your profile.
I've not been a fan of nofollow either. Back on 2005-01-18 at 16:28 Google made the official announcement on nofollow. At that time, it was a band-aid fix to a very large problem, comment spam. I'm sure after its announcement, Google had a pretty clear picture of who was doing what. Brilliant if you ask me.
I could write all day in regards to my thoughts on rel="nofollow" and other related elements, attributes, etc. After nofollow was recently implemented at a popular Social Media Network, I decided to publish my opinion on the use of nofollow. While a noble move, it only touches the "surface".
http://www.seoconsultants.com/sphinn/nofollow/#HistorynofollowAttribute
Funny (and sad) how nofollow...that was "clearly" for one purpose needs an article to track how it has evolved over time!
Is there a small typo in the "robots meta noindex tag"/"Risks? Waste?" section where it states "in conjunction with nofollow" - should this be in conjunction with noindex?
Also could you clarify the header "Consume" please? To me this implies whether the page can acrue page rank from inbound links? Where as I believe this is not the intention in this instance.
Cool resoure :-)
consumes pagerank ... that is used to say whether the strategy blocks the flow of pagerank and/or if it wastes any pagerank on the pages you do not want pagerank to flow to
"I didn't say that using nofollow makes you seem like a spammer"
If you're saying using nofollow makes you seem like an SEO, you're implying nofollow makes you seem like a spammer if you still believe Google thinks SEOs = spammers.
"when you use rel=nofollow to sculpt PageRank you lose plausible deniability that you didn't know what you were doing."
True - that's kind of what nailed David Airey (Matt Cutts decided David knew what he was doing). Aviva directory also got nailed because the siteowner left footprints (e.g. 301 redirecting from an off-topic, expired domain) that took away the luxury of feigning ignorance. But there are differences between a newbie blogger nofollowing outbound links to horde PageRank, Wordpress auto-nofollowing comments to discourage link spam, a big CMS site nofollowing links to a Privacy Policy page, and a seasoned SEO using nofollow specifically to channel PageRank. How would Google tell the difference?
I agree Google's rulebook is intent based (e.g hidden text is ok if a site owner is just trying to optimize user experience). So what is the intent of controlling PageRank flow? One reason would be to move a specific page out of the supp index. I see nothing malicious about that. Google approves of a site owner shifting link weight to important pages. Why? The domain as a whole can't gain more PageRank by sculpting, so PageRank sculpting poses little threat to the SERPs. It's like walking around with $30 bucks, $20 in your right pocket and $10 in your left. No matter how you do it you're still walking around with $30 bucks, no more no less.
There are also hundreds of other quality signals at Google's disposal. Why bother using a signal that will discourage people from using nofollow? Google fought a big uphill crusade trying to get people to feel more comfortable with nofollow. Matt's sculpting PageRank bit was part of that PR campaign. So why unravel all that work just to be able to use one extra signal?
Don't get me wrong; I'm not advocating the use of nofollow (in fact one of my recent post argues against it). I just don't buy the FUD.
They can see how it is used during manual review of the site...when they are viewing the site for other potential issues (was it an advertisement or a paid link? and do they know SEO).
In an environment when hoards of people are looking for "spamming" and a lot is left up to human judgement I think plausable deniability is worth far more than we give it credit for.
I prefer to use rel=nofollow on link then another way.
"They can see how it is used during manual review of the site"
In that case, nofollow may turn into a liability depending on the reviewer. Googlers look for a pattern of manipulative behavior to determine intent, and for some brain-dead reviewers (and I imagine there are more than a few), internal nofollow may fit that pattern.
But unless you're working deep in the gray I don't see any risk, and if you're working completely in the black, I believe its a non-issue.
I think we were in agreement in philosophy there Halfdeck. :)
I have a site where the "disallowed" urls were showing up in the SERPs.
Right now, in Webmaster Tools, they list all the URLs that are "blocked by robots.txt"...and at the same time show (valid) 404 errors for some missing urls that should never have been crawled in the first place!
Question is: why does G crawl urls that it knows it has been disallowed from?
It does not crawl the actual pages that are blocked in robots.txt, but it remembers them and lists them in the search results if it thinks they are relevant for a particular query.
The lame excuse Google uses for such behavior is that some large sites used to block indexing entirely about a decade ago and they are still optimizing their user experience for that point in time rather than current market conditions.
I have a niche site that offers visitors a directory. A few directory listings are paid links. As of my last Google index Aug 6th I have dropped from Googles serps on pages that have ranked high for a couple years. I can see my pages are indexed but they don’t show in the Google results any more. Yahoo and MSN are ok.
Needless to say my traffic is now half of what it was. In no way was I trying to pass along page rank, I was simply trying to provide my visitors with relevant information. After some research, and occasional hair tug, I presume that Google requires the Rel=Nofollow on the links. In my case is this the proper thing to do? Will I see my results come back eventually?
Hi Carl
I answer specific SEO queries in our member forums.
Thanks for the information Aaron. Depending on your suggestions, I made changes to my site and realized that I have not even reached to 1/3 of my site's capability yet. I think your other article titled Wasting Link Authority on Ineffective Internal Link Structure is also very informative with this one.
I am very suspicious about a change that I thought would be a good idea. While I was updating my site, I realized that my breadcrumbs trail was pointing to the '../Default.aspx' along with the logo link. I checked it out, here it is. I have the same PR for 'www.mysite.com/' as 'www.mysite.com/Default.aspx'. Of course, I removed '../Defalt.aspx' from all links pointing my home page. I looked at re-direct options and did some research about it but some posts were saying it causes a loop. So I gave up on that. I was thinking to place '../Default.aspx' in Robots.txt to remove it completely. Do you think that is a good idea? or that will ruin everything? Thank you for any answers in advance.
Just link to the new location rather than an old one...no need to block pages via robots.txt
Aaron, looking at the chart I don't understand how the robots.txt consumes PR. None of the site's pages would normally link to it so how can PR flow to it?
If you block it via robots.txt but still link at the URL it can accumulate PageRank from those links.
When you block URLs from being indexed in Google via robots.txt they may still show those pages as URL only listings in their search results. A better solution for completely blocking the index of a particular page is to use a robots noindex meta tag on a per page bases.
Add new comment